

This guide is not meant to teach you how to write parallel programs on the ODROID-MC1. It is meant to provide you with an environment ready for experimenting with MPJ Express, a reference implementation of the mpiJava 1.2 API. An MPJ Express parallel program that generates Mandelbrot images has been provided for you to run on any machine or cluster that has the the Java SDK installed: ARM or INTEL. If there is sufficient interest expressed for information on MPJ Express programming, we can write a tutorial for a future edition of the magazine.
Why parallel programming?
Parallel programming or computing is a form of computation in which many independent calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved at the same time. In short, its aim includes:
- Increase overall speed,
- Process huge amount of data,
- Solve problems in real time, and
- Solve problems in due time
Why now?
Many people argue whether Moore’s Law still holds. Moore’s law is the observation that the number of transistors in a dense integrated circuit doubles approximately every two years (some say 18 months). Moore’s Law is named after Gordon E. Moore, the co-founder of INTEL and Fairchild Semiconductor. It is this continuous advancement of integrated circuit technology that has brought us from the original 4.77 megahertz PC to the current multi-gigahertz processors. The processor architecture has also changed a lot with multiple execution pipelines, out-of-order execution, caching, etc. Assuming Moore’s Law still applies, we are still faced with big problems in improving our single CPU performance:
- The Power Wall
Power = C * Vdd2 * Frequency
We cannot scale transistor count and frequency without reducing Vdd (supply voltage). Voltage scaling has already stalled.
- The Complexity Wall
Debugging and verifying large OOO (Out-Of-Order) cores is expensive (100s of engineers for 3-5 years). Caches are easier to design but can only help so much.
As an example of the power (frequency) wall, it has been reported that:
- E5640 Xeon (4 cores @ 2.66 GHz) has a power envelope of 95 watts
- L5630 Xeon (4 Cores @ 2.13 GHz) has a power envelope of 40 watts
This implies an increase of 137% electrical power for an increase of 24% of CPU power. At this rate, it is not going to scale. Enter multi-core design. A multi-core processor implements multiprocessing in a single physical package. Instead of cranking up the frequency to achieve higher performance, more cores are put in a processor so that programs can be executed in parallel to gain performance. These days, all INTEL processors are multicore. Even the processors used in mobile phone are all multi-core processors.
Limitations on performance gains
How much improvement can I expect for my application to gain running on a multi-core processor? The answer is that it depends. You application may not have any performance gain at all if it has not been designed to take advantage of multi-core capability. Even if it does, it still depends on the nature of your program and the algorithm it is using. Amdahl’s law states that if P is the proportion of a program that can be made parallel, and (1−P) is the proportion that cannot be parallelised, then the maximum speedup that can be achieved by using N processors is:
- 1/[(1-P) + (P/N)]
The speedup in relation to the number of cores or processors at specific values of P is shown in the graph below.
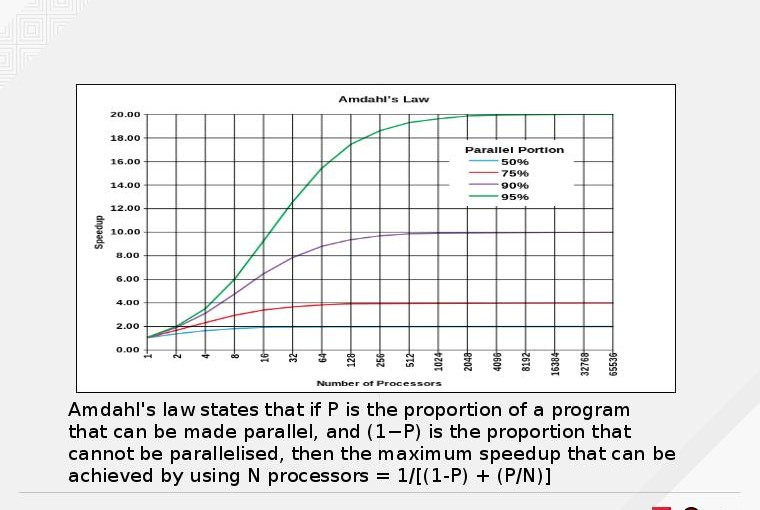
This gives you some perspective on how much performance you may be able to gain by writing your program to take advantage of parallelism instead of having unreal expectations.
Why do parallel programming in Java?
Some of the advantages of writing parallel programs in Java include:
- Write once, run anywhere,
- Large pool of software developers,
- Object Oriented (OO) programming abstractions,
- Compile time and runtime checking of code,
- Automatic garbage collection,
- Supports multi-threading in language, and
- Rich collection of libraries
Java supported multi-threading since its inception, so what is new? Java multithreading uses the Shared Memory Model, meaning that it cannot be scaled to use multiple machines. A Distributed Memory Model refers to a multiprocessor computer system, such as an ODROID-MC1, in which each processor has its own private memory. Computational tasks can only operate on local data, and if remote data is required, the computational task must communicate with one or more remote processors. In contrast, a Shared Memory multiprocessor offers a single memory space used by all processors. Processors do not have to be aware where data resides, except that there may be performance penalties, and that race conditions are to be avoided.
The MPJ Express message passing library
MPJ Express is a reference implementation of the mpiJava 1.2 API, which is the Java equivalent of the MPI 1.1 specification. It allows application developers to write and execute parallel applications for multicore processors and compute clusters using either a multicore configuration (shared memory model) or a cluster configuration (distributed memory model) respectively. The latter also supports a hybrid approach to run parallel programs on a cluster of multicore machines such as the ODROID-MC1. All the software dependencies have already been installed on the SD card image I provided. My mpj-example project on Github My mpj-example project on Github has also been cloned and compiled. The resultant jar file and a dependent file have been copied to the ~/mpj_rundir directory where you can try out in either multicore or cluster mode. All MPJ Express documentations can be found in the $MPJ_HOME/doc directory.
Fractal Generation using MPJ Express
The mpj_example project is a Mandelbrot generator. Mandelbrot set images are made by sampling complex numbers and determining for each number whether the result tends towards infinity when the iteration of a particular mathematical operation is performed. The real and imaginary parts of each number are converted into image coordinates for a pixel coloured according to how rapidly the sequence diverges, if at all. My MPJ Express parallel program assigns each available core to compute one vertical slice of the Mandelbrot set image at a time. Consequently, the more cores are available, the more work can be performed in parallel. Mandelbrot images at specific coordinates are shown in the following images.


These Mandelbrot images are generated using the following commands on a single machine, the master node, using a multicore configuration. From the master command prompt, issue the following commands:

You can rerun the above command with -np values between 1 and 8 inclusive to see the difference in performance by varying the number of cores used for Mandelbrot generation. Remember that the XU4 has 4 little A7 and 4 big A15 cores.
The parameters after com.kardinia.mpj.ColourMandelbrot are:
- parameter 1: starting x coordinate
- parameter 2: starting y coordinate
- parameter 3: step size
- parameter 4: color map for mapping number of iterations to a particular colour
- parameter 5: filename to save the generated mandelbrot
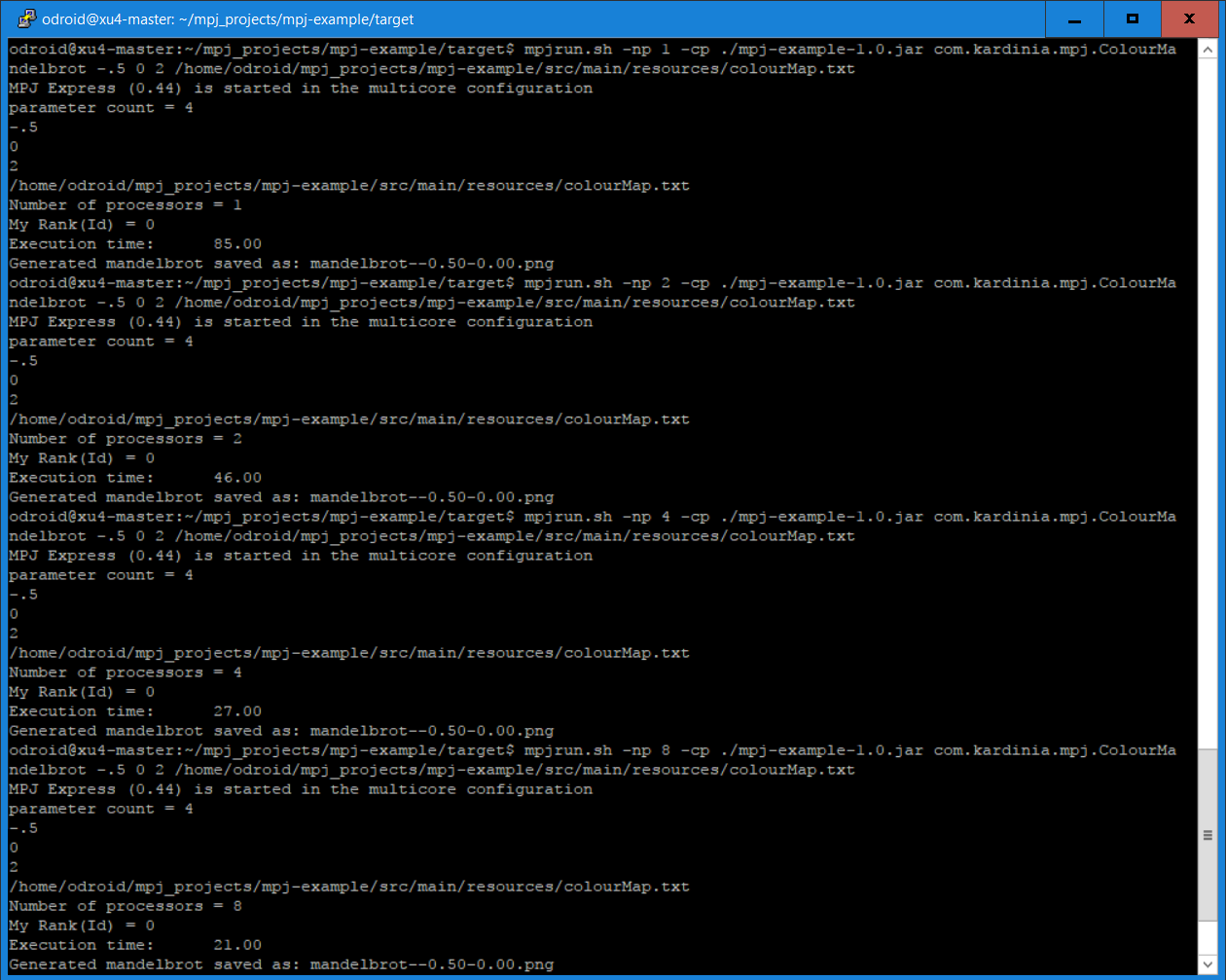
To run the Mandelbrot Generator in cluster mode, follow the instructions below: A text file named “machines” which contains the hostnames of every node in you ODROID-MC1 cluster on separate lines is required. The machines file that is in the ~/mpj_rundir contains the following 4 lines:
xu4-master xu4-node1 xu4-node2 xu4-node3To start the MPJ daemon on each node, issue the command below once from the master node to start a MPJ daemon on each node:
$ mpjboot machinesThen issue the following commands from the master node:

Again, you can vary the number after -np between 4 and 32 as there are a total of 32 cores in your ODROID-MC1 cluster. The screenshot below shows running the above commands in cluster mode.
When you are done with experimenting with the cluster mode, issue the following command from the master to terminate all the MPJ daemons started earlier:
$ cd ~/mpj_rundir $ mpjhalt machines
Performance on the ODROID-MC1
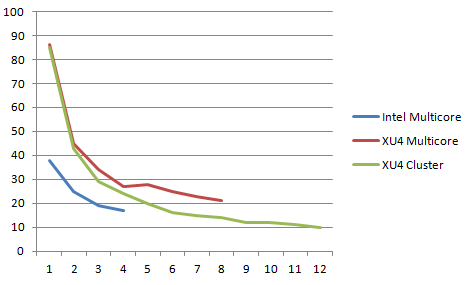
The performance of running the Mandelbrot Generator on the ODROID-MC1 in both multicore and cluster mode is summarised in the line graph below. For comparison, I also ran it on a VM with 4 cores assigned to it on an old INTEL I7 quad core machine. Figure 7 is a screenshot of the generator running in the VM.
The performance of running on INTEL is also shown in the same graph. The vertical axis is the time in seconds taken to generate the Mandelbrot at coordinate -0.5, 0.0. The horizontal axis is the number of cores used.
Graphing the data differently gives the performance increase factor as the number of cores increases.
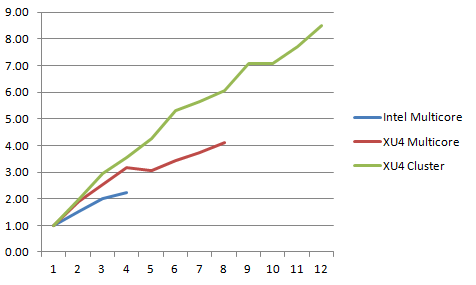
I observed that when a node was using all 4 big cores or all 8 cores, the current used was between 2.0 and 2.5 amps. My cheap power supply was not able to supply enough current when all 4 XU4s on the ODROID-MC1 were running all cores at 100% utilization. This is the reason why I only measured the performance for the cluster configuration up to 12 cores. Another interesting observation was that in multicore mode on a single XU4, the most gain occurred when all 4 big cores were being used. Adding the little cores did not improve performance by that much. Even for cluster mode, the performance gain tapered off as the number of cores increased due to Amdahl’s law as the master had to spend the same amount of time combining the generated partial images into a complete image and it took a finite amount of time to transfer the partial images via the network.
Conclusion
I hope my two getting started guides in the ODROID Magazine have given you some ideas of using your ODROID-MC1 as a Docker swarm cluster and also as a Compute cluster for parallel programming. What you can do with it is limited only by your imagination. Let us know if you are interested in additional information regarding using MPJ Express. We can create additional tutorials. In the meantime, enjoy and keep exploring the capabilities of your ODROID-MC1.
Be the first to comment