

El ODROID-MC1 se ha convertido en un interesante sistema clúster para experimentar, por ejemplo, con implementaciones de swarm Docker [1] y con la minería de criptomonedas [2-4]. Tienes una breve introducción sobre el ODROID-MC1 en la referencia [5]. Un sólo ODROID-MC1 consta de cuatro nodos ODROID-XU4 reducidos, cada uno equipado con un Samsung Exynos 5 Octa (5422). El Exynos 5 Octa es un sistema ARM Big.LITTLE de dos zócalos compuesto por las CPUs Cortex-A15 y Cortex-A7 de cuatro núcleos, con una velocidad de reloj de 2 GHz y 1.4 GHz respectivamente. Las CPU cuentan con multiprocesamiento heterogéneo (HMP). Cada nodo está equipado con 2 GB de LPDDR3 RAM y con una GPU Mali-T628 MP6, que admite OpenGL ES 3.1/2.0/1.1 y el perfil completo OpenCL 1.2. Además, las placas cuentan con Ethernet Gigabit y refrigeración activa por ventilador.
En la referencia [6] tienes una presentación general de la computación con clúster utilizando varios ODROID-XU4s, donde se describe brevemente el concepto de topologías MapReduce. El debate [7] presenta algunos ejemplos de computación paralela de un conjunto Mandelbrot con la librería de paso de mensajes MPJ Express que está implementada en JAVA. En términos de computación científica, JAVA no es la opción más óptima debido a sus limitaciones de rendimiento. En aplicaciones de física e ingeniería, C ++, C o FORTRAN siguen siendo los lenguajes dominantes para escribir código científico [8].
Las simulaciones comunes de última generación emplean cientos de miles de núcleos de CPU en sistemas de computación de alto rendimiento (HPC) [8,9] para resolver grandes desafíos sociales. En este contexto, la escalabilidad y el rendimiento del kernel de simulación son clave para una computación multi-nucleo eficiente, es decir, no solo es esencial contar con un código altamente optimizado que se ejecute de manera eficiente en un único núcleo, sino que también sea posible aumentar la eficiencia informática con un aumento del número de núcleos computacionales. Mientras que el rendimiento de un único núcleo se mejora en general con las técnicas de ajuste del kernel, como la vectorización de bucle, la omisión de errores en la línea de caché y la programación inteligente, la eficiencia paralela se puede medir mediante robustos experimentos de escalado. En estos experimentos, el número de núcleos se duplica continuamente para un problema dado. En el mejor de los casos, el tiempo de resolución se divide con cada duplicado. En este tipo de computación paralela, cada uno de los procesos resuelve un subconjunto del problema original. Con un mayor número de núcleos, también aumenta la sobrecarga de las comunicaciónes de red, lo que conduce a una disminución de la eficiencia. Los mejores códigos de simulación son capaces de escalar desde una pequeña cantidad de núcleos hasta cientos de miles de procesos [8-10].
El ODROID-MC1 puede considerarse como un pequeño sistema HPC y además, es ideal para la simulación de problemas científicos de pequeña y mediana escala. En especil su bajo consumo de energía y su bajo precio lo hacen ideal para el desarrollo de códigos paralelos y para ser adquiridos en departamentos o empresas más pequeñas, o en universidades con fines docentes.
En el siguiente texto se describe cómo configurar un sistema de clúster con un sistema de archivos compartido mediante el Sistema de archivos en red (NFS) y la Interfaz de transmisión de mensajes (MPI) junto con el programador de tareas de clúster SLURM. Se proporcionan ejemplos de cómo ejecutar cálculos paralelos en este sistema. La Mecánica de Fluidos Computacional (CFD) corrobora la aplicabilidad del ODROID-MC1 para resolver problemas científicos. Los pasos que se presentan son los detalles técnicos que están detrás de las simulaciones y los análisis tratados[10].
Configurar el sistema del clúster
El sistema del clúster consta de un nodo frontal, que es un único ODROID-XU4 equipado con un módulo eMMC 5.0 de 16 GB, el ODROID-MC1, un Rackstation RS816 de Synology de 4 bahías, un Switch Ethernet Gigabit de 50 puertos gestionado via Web GSSAE ProSAFE y una puerta de enlace a internet. La Figura 1 muestra una foto de la configuración actual montada en un rack de 19".
El RS816 hace de servidor DHCP y NFS y está conectado al switch con una configuración de conexión con doble puerto. El switch conecta los diferentes componentes. Obviamente, el RS816 y el GS750E pueden ser reemplazados por cualquier otro servidor y switch que tengas la misma funcionalidad, por ejemplo, el propio nodo central (con interfaz de usuario) puede actuar como servidor DHCP y NFS. Para la siguiente explicación, se supone que el acceso a Internet es a través de la puerta de enlace con la IP local 192.168.1.1, el servidor denominado "FS" está instalado y funcionando y éste tiene la dirección IP 192.168.1.2. En este ejemplo, el servidor exporta los tres directorios a través de NFS:
- /homes/ (almacenará los directorios home de los usuarios)
- /netopt/ (contendrá software compartido)
- /work/ (será utilizado como espacio de trabajo para realizar los cálculos)
El nodo central se identificará con el nombre "FE" y se le asignará la IP 192.168.1.100. El resto de nodos del clúster se llamarán CL [1 ... 4] y tendrán las direcciones IP 192.168.1.101 hasta la 192.168.1.104. Primero, vamos a tratar la configuración del nodo central antes abordar la instalación del software genérico y la instalación de los nodos del clúster.

Instalación del nodo central
En primer lugar, Debemos instalar la imagen de Ubuntu Linux en el módulo eMMC del nodo central ODROID-XU4 o en una tarjeta SD. Puedes encontrar una buena explicación paso a paso de este proceso online en [11]. Para el resto de nodos del cluster es suficiente con instalar la imagen mínima de Ubuntu. Ten en cuenta que la instalación del clúster ha sido probada con Ubuntu Linux 16.04 Xenial. Los detalles de la instalación del sistema clúster con Ubuntu Linux 18.04 Bionic la puedes encontrar en la Sec. 5. Para instalar y configurar el nodo central, las tareas que se detallas a continuación deben realizarse como superusuario. Lo primero que debe hacer tras iniciar sesión es fijar una nueva contraseña y generar una clave para iniciar sesión con facilidad
$ passwd $ ssh-keygen -t rsaEsto instalará la clave ssh para root en /root/.ssh/id_rsa. Esta clave será copiada en un paso posterior a los nodos del clúster, permitiendo así una fácil administración de los mismos.
Configuración de la dirección IP y del nombre de host
En el sistema FE, será asiganda la IP fija 192.168.1.100 a través de la actualización del archivo /etc/network/interfaces:
auto lo iface lo inet loopback auto eth0 iface eth0 inet static address 192.168.1.100 gateway 192.168.1.1 netmask 255.255.255.0 dns-nameservers 192.168.1.1El nombre del sistema se puede actualizar añadiendo
FE 192.168.1.100a /etc/hosts y reemplazando odroid en /etc/hostname por FE. Además, para que el sistema sea consciente de la existencia del resto de nodos del clúster, es decir, si tu servidor DHCP no asigna los nombres correctos a los nodos, hay que añadirlos, FS y FE a /etc/hosts también.
CL1 192.168.1.101 CL2 192.168.1.102 CL3 192.168.1.103 CL4 192.168.1.104 FS 192.168.1.2Reiniciar el sistema tiene mucho sentido en esta fase de la configuración.
Instalación y configuración del montador automático
Para montar automáticamente los recursos compartidos del servidor NFS, es necesario instalar el montador automático a través de:
$ apt-get update $ apt-get upgrade $ apt-get install autofsLuego, modifica el archivo /etc/auto/master y añade lo siguiente al final del archivo:
/nfs_mounts /etc/auto.nfsActo seguido, crea el archivo /etc/auto.nfs con el siguiente contenido:
netopt -fstype=nfs,rw,soft,tcp,nolock,uid=user FS:/volume1/shares/netopt homes -fstype=nfs,rw,soft,tcp,nolock,uid=user FS:/volume1/shares/homes work -fstype=nfs,rw,soft,tcp,nolock,uid=user FS:/volume1/shares/workEsto monta los recursos NFS desde el servidor NFS con el nombre de usuario user ubicado en /volume1/shares en el servidor. Ten en cuenta que el nombre de usuario debe existir en ambos sistemas FS y FE. Además, crea los correspondientes directorios:
$ mkdir /nfs_mounts $ mkdir /netopt $ cd /netopt $ ln -s /nfs_mounts/netopt $ cd /home $ ln -s /nfs_mounts/homes/user $ cd /home/user $ ln -s /nfs_mounts/workTen en cuenta que las carpetas /nfs_mounts/netopt, /nfs_mounts/homes y /nfs_mounts/work no existen en este paso, sin embargo, estarán disponibles al iniciar el montador automático. Por lo tanto, ejecuta:
$ service autofs restartTambién tiene sentido que para user y root se agreguen las rutas del software que se instalará en la siguiente sección para las variables de entorno del directorio de búsqueda de rutas. Por lo tanto, añade al archivo ~ /.profile.
$ export PATH=$PATH:/netopt/mpich/bin $ export PATH=/netopt/slurm/bin:$PATH $ export PATH=/netopt/munge/bin:$PATH
Instalación del software para la computación en paralelo del cluster.
Todo el software compartido se instalará en el recurso NFS compartido /netopt. Todas las fuentes se descargarán y configurarán en el subdirectorio /netopt/install. El siguiente paso se realiza en el FE central y asume que hay disponible un compilador como llvm o el compilador GNU.
Instalacion de MPICH
Para permitir el desarrollo de software paralelo, es necesario instalar una librería de comunicación paralela. En este ejemplo, instalaremos la librería MPICH versión 3.2.1, que está disponible en www.mpich.org, con los siguientes comandos:
$ cd /netopt/install $ mkdir mpich $ cd mpich $ tar -xvf mpich-3.2.1 $ cd mpich-3.2.1 $ ./configure --enable-mpi-cxx --prefix=/netopt/mpich-3.2.1 $ make -j 4 $ make install $ cd /netopt $ ln -s mpich-3.2.1 mpich
Instalación y configuración de MUNGE
Para instalar el programador automático de tareas SLURM, debemos instalar los servicios MUNGE (MUNGE 0.5.13; disponibles en https://dun.github.io/munge/). MUNGE es un servicio de autentificación para crear y validar credenciales que es necesario para la programación autentificada. Para instalar MUNGE primero escribe
$ apt-get install mungeEsto permite tener a mano todos los scripts de inicio y de ejecución de servicios necesarios. Para instalar, sin embargo, la última versión de MUNGE, el código fuente que hemos mencionado anteriormente se descarga y almacena en /netopt/install. Para compilar MUNGE e instalarlo ejecuta:
$ cd /netopt/install $ mkdir munge $ cd munge $ tar -xvf munge-0.5.13.tar.gz $ cd munge-munge-0.5.13 . $ /configure --prefix=/netopt/munge-0.5.13 $ make -j 4 $ make install $ cd /netopt $ ln -s munge-0.5.13 munge $ cd munge $ mv etc etc.old $ mv var var.old $ ln -s /etc $ ln -s /varTenga en cuenta que los registros log de MUNGE se escribirán en el sistema de archivos local /var y la configuración se realizará en /etc. Para configurar MUNGE, debe generarse una clave secreta MUNGE:
$ dd if=/dev/random bs=1 count=1024 > /etc/munge/munge.keyTen en cuenta que en un paso posterior (consulta la Sección 2.3.2), el archivo /etc/munge/munge.key se copiará al resto de nodos del clúster. Además, dado que la instalación compilada de MUNGE reemplaza la versión previamente instalada, el enlace al ejecutable de MUNGE debe actualizarse:
$ cd /usr/sbin $ mv munged munged.old $ ln -s /netopt/munge/sbin/munged
Instalación de PMIX
Otra herramienta que debe instalarse es PMIX (en este caso PMIX 2.1.0; disponible en https://github.com/pmix/pmix/releases):
$ cd /netopt/install $ mkdir pmix $ cd pmix $ tar -xvf pmix-2.1.0.tar.gz $ cd pmix-2.1.0 $ ./configure --prefix=/netopt/pmix-2.1.0 $ make -j 4 $ make install $ cd /netopt $ ln -s pmix-2.1.0 pmix
Instalación y configuración de SLURM
Finalmente, instalaremos el programador SLURM (SLURM 17.11.3-2; disponible en https://slurm.schedmd.com). Similar a MUNGE, primero instalaremos Ubuntu SLURM con
$ apt-get slurm-llnl libslurm-devDespues, instalaremos la última versión en /netopt con
$ cd /netopt/install
$ mkdir slurm
$ cd slurm
$ tar -xvf slurm-17.11.3-2.tar.gz
$ cd slurm-17.11.3-2
$ ./configure --prefix=/netopt/slurm-17.11.3-2 --sysconfdir=/etc/slurm-llnl --with-munge=/netopt/munge \
--with-pmix=/netopt/pmix
$ make -j 4
$ make install
$ cd /netopt
$ ln -s slurm-17.11.3-2 slurm
Para configurar SLURM, el archivo /etc/slurm-llnl/slurm.conf debe modificarse con
# GENERAL ControlMachine=FE AuthType=auth/munge CryptoType=crypto/munge MpiDefault=none ProctrackType=proctrack/pgid ReturnToService=1 SlurmctldPidFile=/var/run/slurm-llnl/slurmctld.pid SlurmdPidFile=/var/run/slurm-llnl/slurmd.pid SlurmdSpoolDir=/var/spool/slurmd SlurmUser=slurm StateSaveLocation=/var/spool/slurmctld SwitchType=switch/none TaskPlugin=task/affinity TaskPluginParam=sched # SCHEDULING FastSchedule=1 SchedulerType=sched/backfill SelectType=select/cons_res SelectTypeParameters=CR_Core # LOGGING AND ACCOUNTING AccountingStorageType=accounting_storage/none ClusterName=odroid JobAcctGatherType=jobacct_gather/none SlurmctldDebug=verbose SlurmctldLogFile=/var/log/slurmctld.log SlurmdDebug=verbose SlurmdLogFile=/var/log/slurmd.log # COMPUTE NODES NodeName=CL[1-4] CPUs=8 RealMemory=1994 State=UNKNOWN PartitionName=batch Nodes=CL[1-4] OverSubscribe=EXCLUSIVE Default=YES MaxTime=INFINITE State=UPEn /usr/sbin, actualiza los siguientes enlaces:
$ cd /usr/sbin $ mv slurmctld slurmctld.old $ mv slurmd slurmd.old $ mv slurmstepd slurmstepd.old $ ln -s /netopt/slurm/sbin/slurmctld $ ln -s /netopt/slurm/sbin/slurmd $ ln -s /netopt/slurm/sbin/slurmstepdAdemás, asegúrate de añadir la siguiente carpeta y cambiar los permisos de la siguiente forma
$ mkdir /var/spool/slurmctld $ chown slurm:slurm /var/spool/slurmctld
Instalación de los nodos del clúster
Los nodos del cluster usan la imagen mínima de Ubuntu Linux. La siguiente configuraicón se muestra a modo de ejemplo para el primer nodo de clúster CL1 con IP 192.168.1.101 y ésta debe aplicarse a todos los nodos de clúster.
Configuración general del nodo del clúster
Tras la instalación de la tarjeta SD, asegúrate de actualizar el sistema:
$ apt-get update $ apt-get upgrade $ apt-get dist-upgradeAsegúrate también de copiar la carpeta /root/.ssh de FE a CL1, es decir, en FE ejecuta lo siguiente (asegúrate de que rsync esté instalado):
$ rsync -av /root/.ssh CL1:/root/Luego, sigue los pasos de la sec. 2.1.1 y sec. 2.1.2 para tener la dirección IP correcta (192.168.1.101), el nombre de host (CL1) y el montador automático activado.
Integración del sistema cluster
Instala todos los paquetes necesarios en CL1:
$ apt-get install munge slurm-llnl libslurm-devDespués, la clave MUNGE generada en la sec. 2.2.2 y que se encuentra dentro de /etc/munge/munge.key en FE y el archivo de configuración SLURM que se encuentra en /etc/slurm-llnl/slurm.conf deben transferirse a CL1 ejecutando:
$ rsync -av /etc/munge/munge.key CL1:/etc/munge/ $ rsync -av /etc/slurm-llnl/slurm.conf CL1:/etc/slurm-llnl/en FE. En este paso tiene sentido reiniciar el nodo del clúster. Después de instalar cada nodo, el sistema está casi listo para realizar carculos.
Administración del clúster
Para que el planificador de tareas se ejecute, debemos ejecutar los siguientes comandos en los nodos
$ sudo service munge start $ sudo service slurmd starty en FE:
$ sudo service munge start $ sudo service slurmctld startSe puede comprobar el estado del nodo con:
$ scontrol show nodeso con:
$ sinfo -N --longSi uno de los nodos se encuentra en estado DOWN o UNKNOWN, se puede reanudar mediante
$ scontrol update NodeName=NAME State=RESUMEdonde NAME es el nombre del nodo, por ejemplo, CL1.
Envío de tareas
Ahora que el clúster es completamente funcional, podemos enviar tareas al programador, el cual necesita un archivo de trabajo como:
#!/bin/bash -x
#SBATCH --nodes=4 // allocates 4 nodes for the job
#SBATCH --ntasks-per-node=2 // starts 2 MPI ranks per node
#SBATCH --cpus-per-task=4 // for each MPI rank per node 4 OpenMP threads are reserved
#SBATCH --output=mpi-out.%j // location of the output file
#SBATCH --error=mpi-err.%j // location of the error file
#SBATCH --time=00:20:00 // wall time of the job
#SBATCH --partition=batch // the name of the partition
export OMP_NUM_THREADS=${SLURM_CPUS_PER_TASK} // information for OpenMP
srun --mpi=pmi2 COMMAND // runs the command COMMAND in parallel
Las tareas se pueden programar para los nodos de diferentes formas, es decir, se puede usar para el cálculo los núcleos de forma individual, los núcleos Cortex-A7 (lentos) o los Cortex-A15 (rápidos), o ambos. Todo esto se configura con el comando srun en el script de trabajo:
srun --cpu-bind=verbose,mask_cpu:ABxCD --mpi=pmi2 COMMAND // uses mask ABxCD for schedulingLa opción mask_cpu permite especificar la máscara para la ejecución. Las máscaras para usar un único sistema Cortex o los dos se muestran en las Tablas 1 y 2.
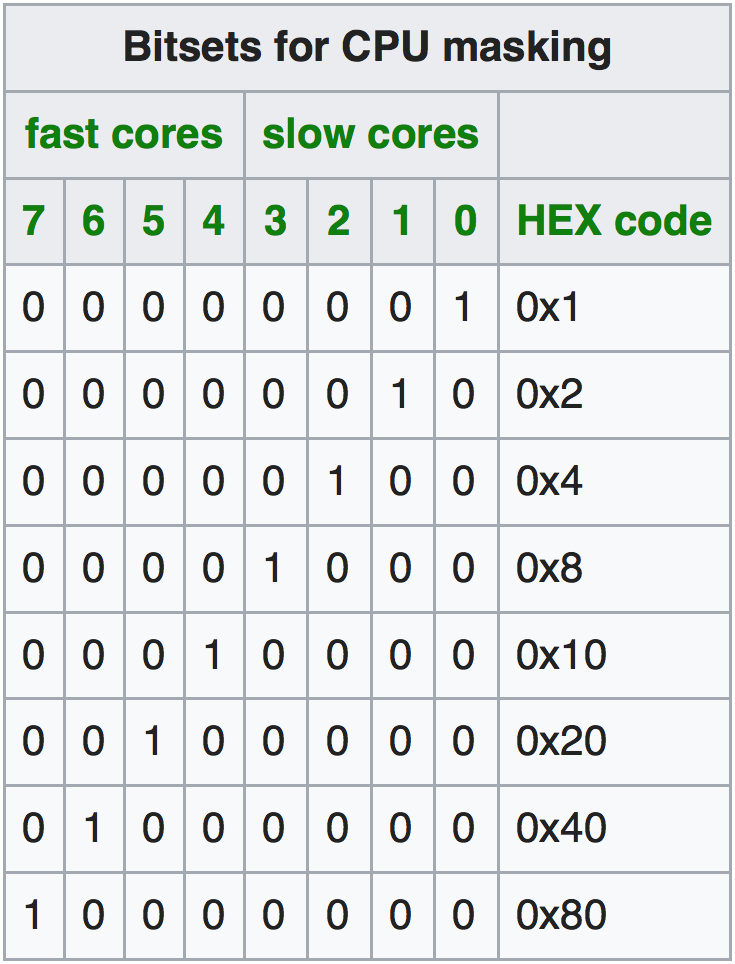
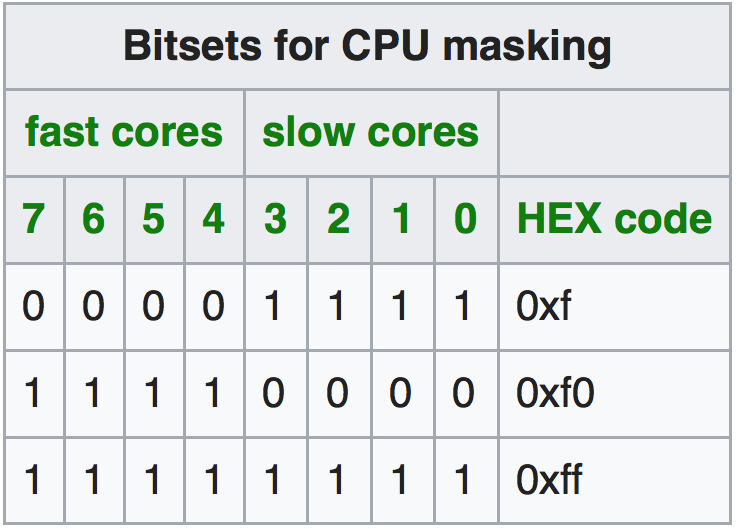
Ejemplo: Simulación de flujo en el ODROID-MC1
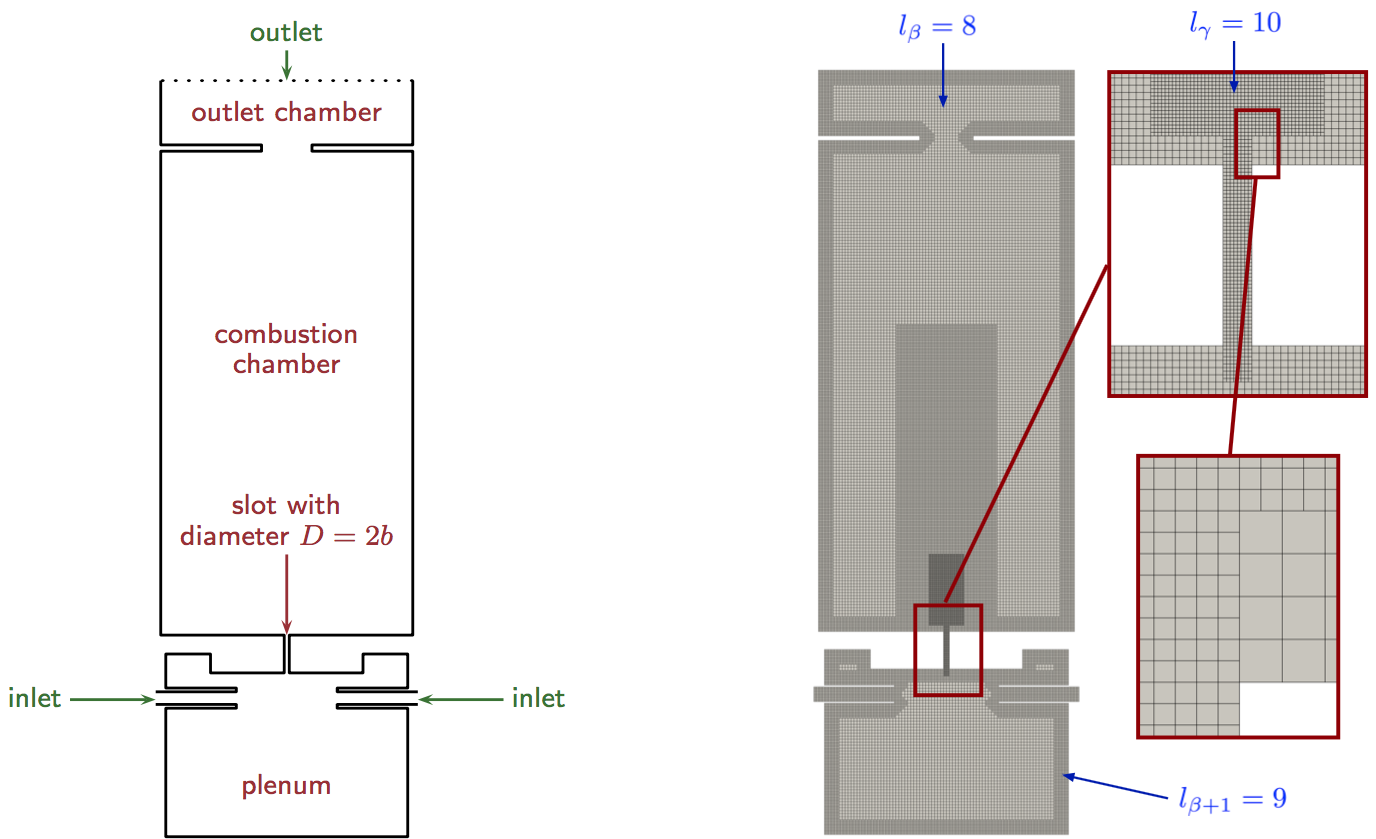
Para demostrar que el sistema ODROID-MC1 se puede utilizar para llevar a cabo simulaciones científicas, a continuación, se muestra un ejemplo de simulación de flujo en una geometría de quemado [10]. Ver la Fig. 2; Lado izquierdo. La simulación utiliza un código de red-Boltzmann [12], que resuelve las ecuaciones de control de la mecánica de fluidos sobre una malla cartesiana que discrimina el espacio, es decir, la ecuación de Boltzmann se resuelve para todas las ubicaciones espaciales dentro de esta malla en el tiempo.
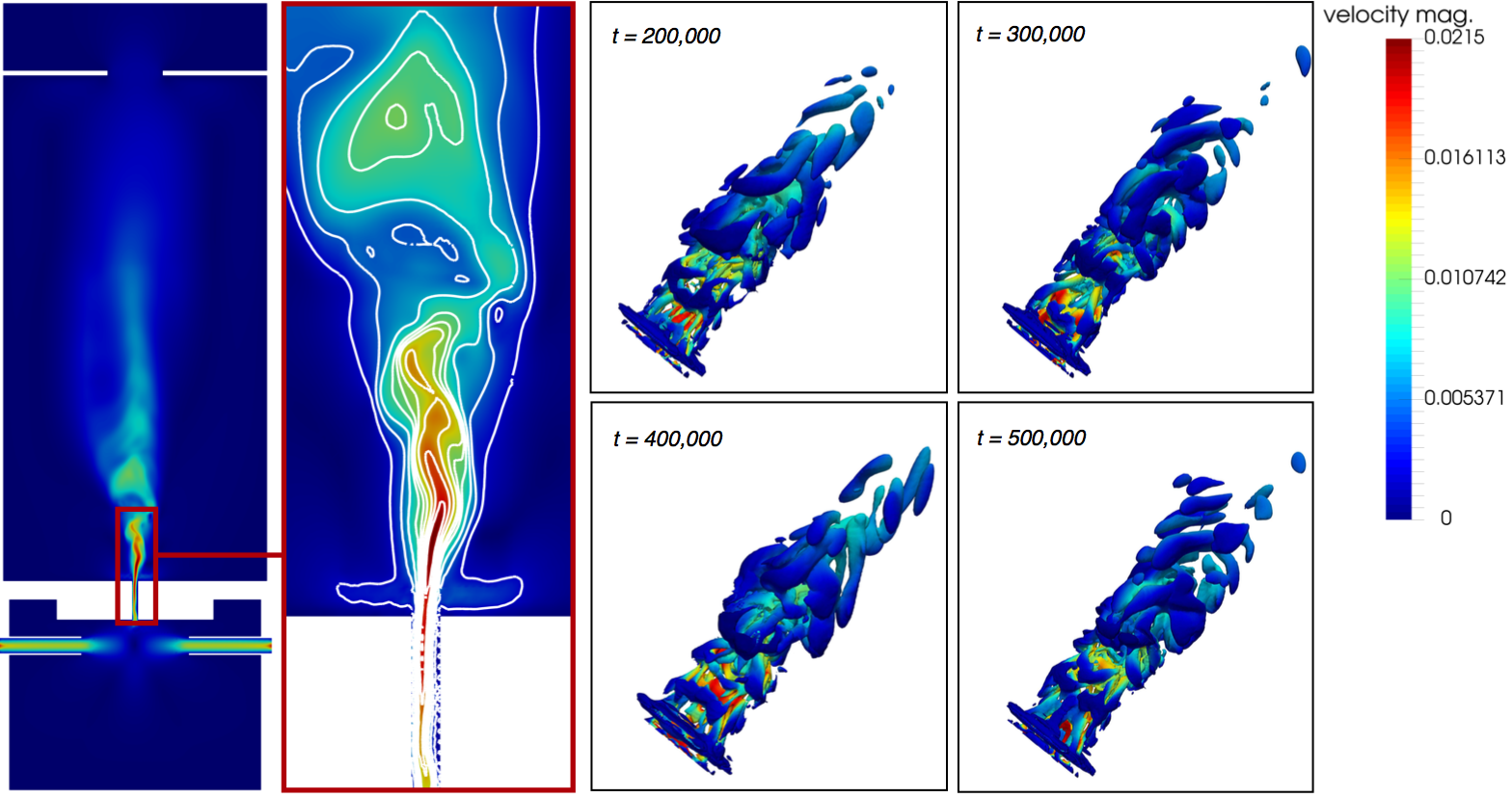
En cada paso de tiempo, en cada ubicación de la malla, se calcula un vector de velocidad y densidad mediante un algoritmo de dos etapas que simula localmente la colisión de partículas en un volumen finito y transporta la información de colisión a las ubicaciones vecinas. La malla es generada por un generador de malla paralelo [13] que se muestra en la Fig. 2 en el lado derecho. Especialmente proximo a las paredes y en la región del chorro de combustión, la malla se refina localmente para tener una resolución suficiente como para capturar las principales características de flujo. La Figura 3 muestra los resultados del cálculo, generado utilizando únicamente los núcleos más rápidos Cortex-A15 del ODROID-MC1. La simulación se ejecuta durante 24 horas. Obviamente, un chorro avanza por la región de la ranura que llega hasta la cámara de combustión. A la izquierda se muestra una sección transversal en la región de la ranura con contornos de la magnitud de la velocidad. El lado derecho muestra contornos tridimensionales de las estructuras voraginosas generadas en diferentes pasos de tiempo de la simulación. Como he mencionado en la introducción, la escalabilidad es un aspecto importante en las simulaciones HPC. Por ello, se suelen realizan intensas mediciones de escalabilidad para todo el sistema.
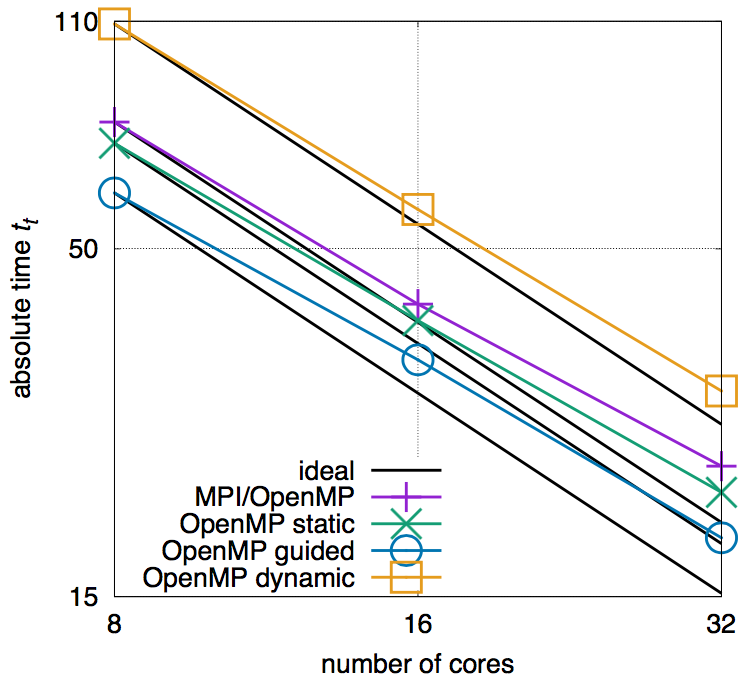
La Figura 4 muestra la escalabilidad de la simulación utilizando diferentes estrategias de paralelización, es decir, utilizando una simple MPI y estrategias de paralelización híbridas MP/OpenMP, esta última con diferentes opciones de programación OpenMP para bucles paralelos. Las líneas negras representan el comportamiento de la escala ideal. En la Figura 4 se puede ver que, entre todos los casos, la MPI/OpenMP híbrida que utiliza las estrategias de paralelización de bucle guiado es la que mejor funciona y, por lo tanto, es la técnica elegida para la simulación. El efecto de la sobrecarga de comunicación ya es visible desde la discrepancia hasta la línea negra ideal. Sin embargo, esta configuración no supera el rendimiento de solo usar los núcleos rápidos Cortex-A15 (tal y como se usa para la simulación de quemado). Para más detalles, el lector interesado puede dirigirse a la referencia [10] de donde se han tomado los resultados y que, además, analice el consumo de energía del ODROID-MC1 y compare su rendimiento con los sistemas HPC alemanes de última generación.
Resumen y conclusión
El ODROID-MC1 es un sistema prometedor para el funcionamiento de un clúster y para la simulación de pequeños y medianos problemas científicos. La correspondiente instalación del software es sencilla. Este articulo nos ha proporcionado un manual paso a paso sobre cómo configurar el sistema de clúster para llevar a cabo computación paralela utilizando MPI con MPICH y PMIX. El programador automático de tareas SLURM utiliza MUNGE para la autentificación y permite fijar tareas para ejecutar simple trabajos MPI y MPI/OpenMP híbrido. Un ejemplo de simulación de flujo en una configuración de quemado ha demostrado que el ODROID-MC1 es un sistema adecuado para la simulación de tipo de problemas. La escalabilidad del software de simulación en el sistema es mas que suficiente para calcular soluciones en un tiempo razonable. Es decir, para los pequeños departamentos o grupos de investigación el ODROID-MC1 es una alternativa rentable frente a los sistemas HPC basados en x86 si las simulaciones a gran escala no son el objetivo principal.
Comentarios adicionales
En lugar de instalar cada nodo del clúster de forma individual, también es posible instalar el arranque PXE y hacer que cada nodo arranque a través de la red desde TFTP. El sistema de archivos root se importa a través de NFS desde un servidor de archivos. Puedes encontrar una guía detallada sobre cómo configurar el arranque PXE en ODROID-XU4 en las páginas de la Wiki de ODROID [14]. Usando la última versión de Linux Ubuntu 18.04 Bionic, son necesarios realizar algunos cambios en el proceso de instalación. En primer lugar, la configuración de la red ha cambiado de una configuración en /etc/network/interfaces a una configuración a través de netplan. Es decir, en lugar de modificar /etc/network/interfaces, debe crearse el archivo /etc/netplan/01-networkd.yaml con el siguiente contenido (ejemplo para CL1)
network:
ethernets:
eth0:
addresses: [192.168.1.101/24]
gateway4: 192.168.1.1
nameservers:
addresses: [192.168.1.1]
dhcp4: no
version: 2
Asegúrate de no usar tabulaciones en el archivo para el sangrado. Después de esto puedes ejecutar
$ netplan apply $ netplan --debug applyque debería cambiar tu IP de inmediato. Además, la versión SLURM en el repositorio de Ubuntu en Bionic es diferente, la cual necesitas instalar
$ apt-get install slurm-wlmen lugar del paquete slurm-llnl. Este todavía proporciona la misma estructura de directorios que slurm-llnl, así que no hay que hacer más cambios.
Referencias
[1] A. Yuen, ODROID-MC1 Docker Swarm: Getting Started Guide, Odroid Magazine (46)(2017)
[2] E. Kisiel, Prospectors, Miners, and 49er’s: Dual GPU-CPU Mining on the ODROID-XU4/MC1/HC1/HC2, Odroid Magazine (51)(2018).
[3] E. Kisiel, Prospectors, Miners, and 49er’s - Part 2: Dual GPU-CPU Mining on the ODROID-XU4/MC1/HC1/HC2, Odroid Magazine (52)(2018).
[4] E. Kisiel, Prospectors, Miners, and 49er’s - Part 3: Operation and Maintenance of Crypto-Currency Mining Systems, Odroid Magazine (53)(2018).
[5] R. Roy, ODROID-HC1 and ODROID-MC1: Affordable High-Performance And Cloud Computing At Home, Odroid Magazine (45)(2017).
[6] M. Kamprath, ODROID-XU4 Cluster, Odroid Magazine (53)(2018).
[7] A. Yuen, ODROID-MC1 Parallel Programming: Getting Started, Odroid Magazine (46)(2017).
[8] D. Brömmel, W. Frings, B. J. N. Wylie, B. Mohr, P. Gibbon, T. Lippert, The High-Q Club: Experience Extreme-scaling Application Codes. Supercomputing Frontiers and Innovations, 5(1), 59–78 (2018). doi:10.14529/jsfi180104
[9] A. Pogorelov, M. Meinke, W. Schröder, Cut-cell method based large-eddy simulation of tip-leakage flow. Physics of Fluids, 27(7), 075106 (2015). doi:10.1063/1.4926515
[10] A.Lintermann, D. Pleiter, W. Schröder, Performance of ODROID-MC1 for scientific flow problems, Future Generation Computer Systems (in press, first online: Jan. 04, 2019). doi:10.1016/j.future.2018.12.059
[11] Odroid Wiki https://wiki.odroid.com/troubleshooting/odroid_flashing_tools
[12] R.K. Freitas, A. Henze, M. Meinke, W. Schröder, Analysis of Lattice-Boltzmann methods for internal flows. Computers & Fluids, 47(1), 115–121 (2011). doi:10.1016/j.compfluid.2011.02.019
[13] A. Lintermann, S. Schlimpert, J. H. Grimmen, C. Günther, M. Meinke, W. Schröder, W. Massively parallel grid generation on HPC systems, Computer Methods in Applied Mechanics and Engineering 277, 131–153 (2014). doi:10.1016/j.cma.2014.04.009
[14] PXE boot on ODROID-XU4/MC1/HC1, https://wiki.odroid.com/odroid-xu4/application_note/software/pxe_boot
Be the first to comment