

Esta guía no pretende enseñarte a escribir programas en paralelo sobre el ODROID-MC1. Está dirigida a proporcionarte un entorno acondicionado para experimentar con MPJ Express, una implementación de referencia de la API mpiJava 1.2. Se proporciona un programa paralelo en MPJ Express que genera imágenes Mandelbrot para que se ejecute en cualquier máquina o clúster que tenga instalado el SDK de Java: ARM o INTEL. En el caso de que exista mucho interés por conocer la programación MPJ Express, podemos escribir un tutorial para una futura edición de la revista.
¿Por qué la programación en paralelo?
La programación o la computación en paralelo es un modo de procesamiento en el cual muchos cálculos independientes se llevan a cabo de forma simultánea, operando bajo la premisa de que los grandes problemas a menudo se pueden dividir en pequeños, y que luego se resuelven al mismo tiempo. En resumen, lo que persigue es tipo de programación es:
- Aumentar la velocidad general,
- Procesar gran cantidad de datos,
- Resolver problemas en tiempo real y
- Solucionar problemas a su debido tiempo
¿Por qué ahora?
Mucha gente debate si la Ley de Moore todavía se mantiene. La ley de Moore viene a decir que el número de transistores en un denso circuito integrado se duplica aproximadamente cada dos años (algunos dicen que 18 meses). La ley de Moore debe su nombre a Gordon E. Moore, cofundador de INTEL y Fairchild Semiconductor. Es este continuo avance de la tecnología de circuitos integrados el que nos ha llevado a pasar del PC original de 4,77 megahertz a los actuales procesadores multi-gigahertz. La arquitectura de los procesadores también ha cambiado mucho con los múltiples hilos de ejecución, la ejecución fuera de orden, el almacenamiento en caché, etc. Suponiendo que la ley de Moore se siga aplicando, nos enfrentamos a grandes problemas para mejorar el rendimiento de la CPU:
-
El Muro de la Potencia
Potencia = C * Vdd2 * Frecuencia
No podemos seguir escalando la cantidad de transistores y la frecuencia sin reducir el Vdd (voltaje de alimentación). El escalado del voltaje ya se ha estancado.
- El Muro de la Complejidad
Depurar y verificar los grandes núcleos OOO (Out-Of-Order) es costoso (100 ingenieros durante 3-5 años). Las cachés son más fáciles de diseñar, pero solo pueden ayudar hasta cierto punto.
Como ejemplo del problema de la potencia (frecuencia), tenemos que:
- E5640 Xeon (4 núcleos @ 2.66 GHz) tiene una sobre carga de potencia de 95 vatios.
- L5630 Xeon (4 núcleos @ 2.13 GHz) tiene una sobre carga de potencia de 40 vatios.
Esto implica un aumento del 137% de potencia eléctrica para un aumento del 24% de la potencia de la CPU. A este ritmo, no se va a poder escalar. Entra en escena el diseño de los multinúcleos. Un procesador multinúcleo ejecuta el multiprocesamiento en un único paquete físico. En lugar de aumentar la frecuencia para lograr un mayor rendimiento, se colocan más núcleos en un procesador para que los programas se puedan ejecutar en paralelo y así aumentar el rendimiento. En la actualidad, todos los procesadores INTEL son multinúcleo. Incluso los procesadores utilizados en los teléfonos móviles son todos procesadores con múltiples núcleos.
Limitaciones en las mejoras de rendimiento
¿Cuánta mejora puedo esperar de mi aplicación si logro que se ejecute en un procesador multinúcleo? La respuesta es que depende. Es posible que tu aplicación no tenga ninguna mejora de rendimiento si no se ha diseñado específicamente para aprovechar el potencial de múltiples núcleos. Incluso si lo hace, todavía depende de la propia naturaleza del programa y del algoritmo que utilice. La ley de Amdahl establece que si P es la proporción de un programa que se puede hacer en paralelo, y (1-P) es la proporción de que no se puede poner en paralelo, entonces la aceleración máxima que se puede alcanzar utilizando N procesadores es:
- 1/[(1-P) + (P/N)]
La aceleración en relación al número de núcleos o procesadores con valores específicos de P se muestra en el siguiente gráfico.
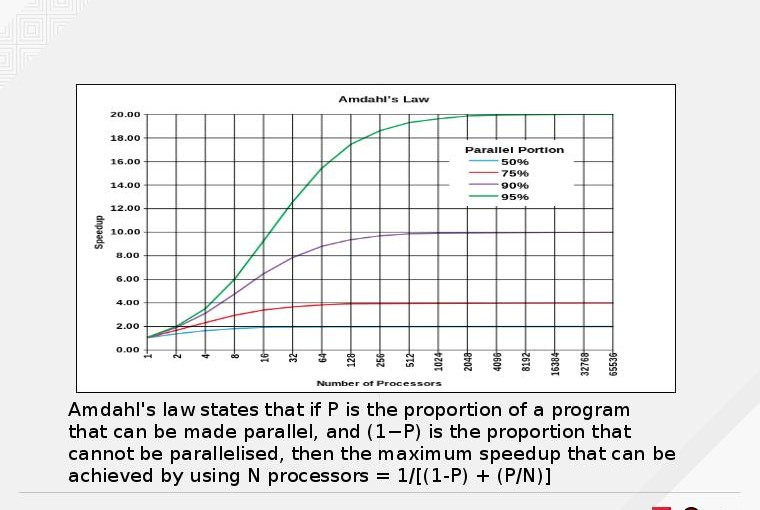
Esto te puede dar una cierta idea de cuánto rendimiento puedes llegar a alcanzar a la hora de escribir tu programa pudiendo aprovechar la programación en paralelo en lugar de tener expectativas pocos realistas
W¿Por qué hacer programación paralela en Java?
Algunas de las ventajas de escribir programas java en paralelo son:
- Se escribe una vez, se ejecuta en cualquier lugar,
- Colectivo muy extenso de desarrolladores de software,
- Programación orientada a objetos (OO),
- Verificación del código en tiempo de ejecución y tiempo de compilación,
- Recogida automática de basura (información no válida),
- Soporte para múltiples hilos de ejecución (multi-threading) en el lenguaje y
- Amplia colección de librerías
Java soporta múltiples hilos de ejecución desde sus inicios, entonces, ¿qué hay de nuevo? El multi-hilo Java utiliza el modelo de memoria compartida, lo que significa que no se puede escalar para usar varias máquinas.
Un modelo de memoria distribuida hace referencia a un sistema informático multiprocesador, como un ODROID-MC1, en el que cada procesador tiene su propia memoria privada. Las tareas informáticas solo pueden incidir en datos locales, y si se requieren datos remotos, las tareas informáticas debe comunicarse con uno o más procesadores remotos. En cambio, un multiprocesador de memoria compartida ofrece un único espacio de memoria que es usado por todos los procesadores. Los procesadores no tienen que estar pendientes de dónde residen los datos, excepto que pueden tener penalizaciones de rendimiento, y que deben evitar condiciones de competición (Procesador más rápido).
La Librería MPJ Express Paso de Mensajes
MPJ Express es una implementación de referencia de la API mpiJava 1.2, que es el equivalente de Java de la especificación MPI 1.1. Permite a los desarrolladores de aplicaciones escribir y ejecutar aplicaciones en paralelo para procesadores multinucleo y clústeres que utilicen una configuración multinúcleo (modelo de memoria compartida) o una configuración de clúster (modelo de memoria distribuida) respectivamente. Este último también es compatible con una técnica híbrida para ejecutar programas en paralelo en un clúster de máquinas multinúcleo, como el ODROID-MC1. Todas las dependencias de software ya han sido instaladas en la imagen para tarjetas SD que proporciono Mi proyecto mpj-example en Github también ha sido clonado y compilado. Se ha copiado un archivo jar resultante y un archivo dependiente en el directorio ~/mpj_rundir donde puede probar en modo clúster o multicore. Toda la documentación sobre de MPJ Express la puedes encontrar en el directorio $MPJ_HOME/doc
Generación de Fractal usando MPJ Express
El proyecto mpj_example es un generador Mandelbrot. Las imágenes de conjunto Mandelbrot se obtienen muestreando números complejos y determinando para cada número si el resultado tiende hacia el infinito cuando se ejecuta la reiteración de una operación matemática particular. Las partes imaginarias y reales de cada número se convierten en coordenadas de imagen para un píxel de color según la rapidez con la que la secuencia diverge, o en nada en absoluto. Mi programa paralelo MPJ Express asigna cada núcleo disponible para que calcule un trozo vertical de la imagen del conjunto Mandelbrot a la vez. En consecuencia, cuantos más núcleos haya disponibles, más trabajo se puede realizar en paralelo. Las imágenes de Mandelbrot en coordenadas específicas se muestran en las siguientes imágenes.


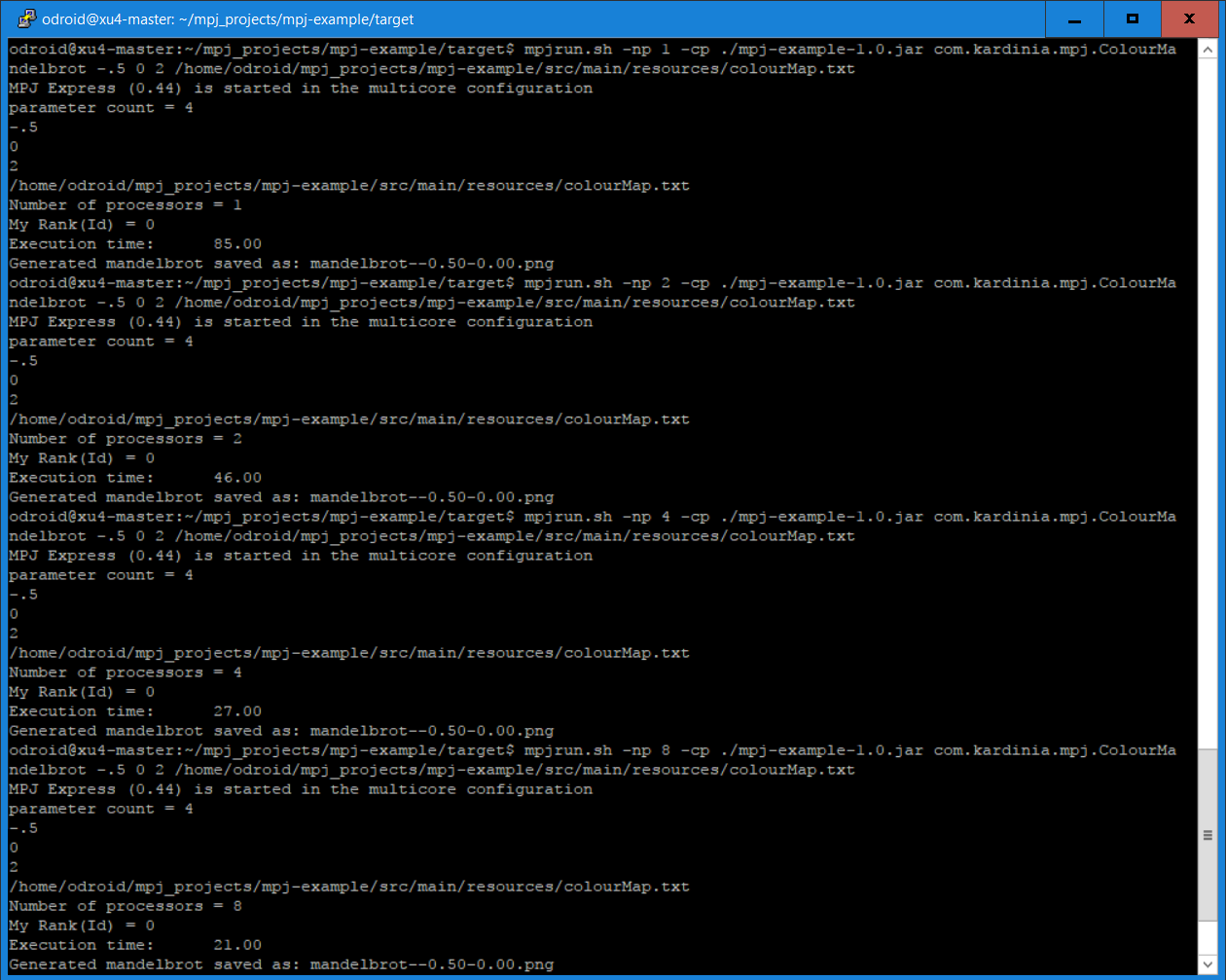
Estas imágenes de Mandelbrot son generadas usando los siguientes comandos en una única máquina, el nodo maestro, utilizando una configuración multinúcleo. Desde el prompt del nodo maestro, introduce los siguientes comandos:

Puedes volver a ejecutar el comando anterior con valores -np entre 1 y 8 inclusive para ver la diferencia de rendimiento al variar la cantidad de núcleos utilizados para la generación de Mandelbrot. Recuerda que el XU4 tiene 4 núcleos pequeños A7 y 4 grandes núcleos A15.
Los parámetros que aparecen después de com.kardinia.mpj.ColourMandelbrot son:
- parámetro 1: inicio de coordenada x
- parámetro 2: inicio de coordenada y
- parámetro 3: tamaño del paso
- parámetro 4: mapa de color para asignar el número de iteraciones a un color en particular
- parámetro 5: nombre de archivo para guardar el mandelbrot generado
Para ejecutar el generador de Mandelbrot en modo clúster, sigue las siguientes instrucciones: Se necesita un archivo de texto llamado "máquines" que contenga los nombres de host de cada nodo de tu clúster ODROID-MC1 en líneas independientes. El archivo que se encuentra en ~/mpj_rundir contiene las siguientes líneas:
xu4-master xu4-node1 xu4-node2 xu4-node3Para iniciar el demonio MPJ en cada nodo, ejecuta el siguiente comando una vez desde el nodo maestro para iniciar un demonio MPJ en cada nodo:
$ mpjboot machinesLuego envía los siguientes comandos desde el nodo maestro:

Una vez más, puedes variar el número que aparece después de -np entre 4 y 32, ya que hay un total de 32 núcleos en tu clúster ODROID-MC1. La siguiente captura de pantalla muestra la ejecución de los comandos anteriores en el modo clúster.

Cuando hayas terminado de experimentar con el modo de clúster, introduce el siguiente comando en el sistema maestro para finalizar todos los demonios MPJ iniciados anteriormente:
$ cd ~/mpj_rundir $ mpjhalt machines
Rendimiento en el ODROID-MC1
El rendimiento de la ejecución del generador de Mandelbrot en ODROID-MC1 tanto en modo multinúcleo como en modo clúster se resume en las siguientes gráficas. Para hacer una comparación, también lo ejecuté en una máquina virtual con 4 núcleos asignados a ésta en una vieja máquina INTEL I7 quad core. Aquí tienes una captura de pantalla del funcionamiento del generador en la máquina virtual.
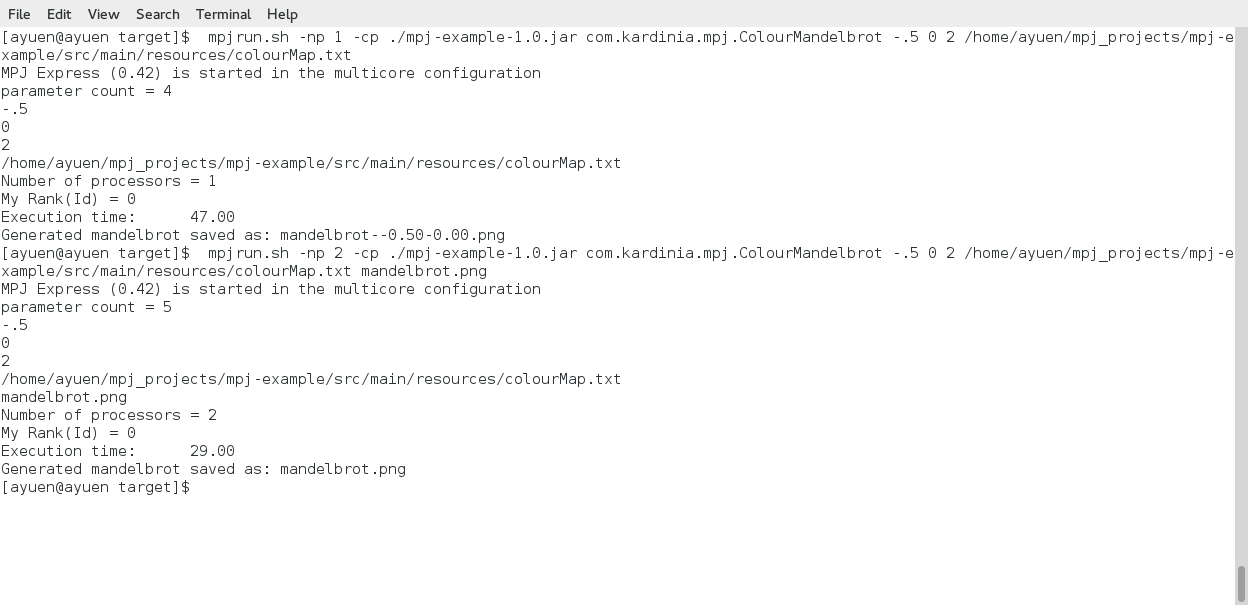
El rendimiento de la ejecución en INTEL también se muestra en la misma gráfica. El eje vertical es el tiempo en segundos que se necesita para generar el Mandelbrot en la coordenada -0.5, 0.0. El eje horizontal es la cantidad de núcleos utilizados.

Representar gráficamente los datos de un modo diferente nos proporciona el coeficiente de incremento del rendimiento a medida que aumenta el número de núcleos.
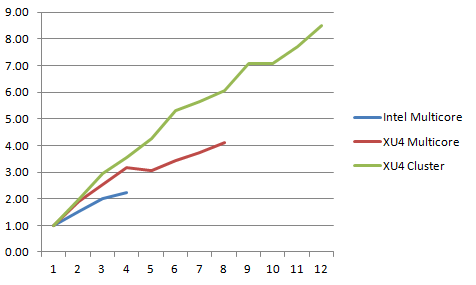
Observé que cuando un nodo estaba usando los 4 núcleos grandes o los 8 núcleos, la corriente utilizada estaba entre 2.0 y 2.5 amperios. Mi barata fuente de alimentación no era capaz de suministrar suficiente corriente cuando los 4 XU4s en el ODROID-MC1 ejecutaban todos los núcleos al 100%. Esta es la razón por la que solo medí el rendimiento de la configuración del clúster hasta 12 núcleos. Otra cuestión interesante que observé fue que en el modo multinúcleo en un solo XU4, el mayor incremento de rendimiento se produjo cuando se utilizaron los 4 núcleos grandes. Añadir los pequeños núcleos apenas mejoró el rendimiento. Incluso en el modo clúster, el aumento de rendimiento se redujo a medida que la cantidad de núcleos aumentaba debido a la ley de Amdahl, ya que el sistema maestro tenía que dedicar la misma cantidad de tiempo combinando las imágenes parciales generadas en una imagen completa y disponía de un tiempo limitado para transferir las imágenes parciales a través de la red.
Conclusión
Espero que mis dos guías de inicio en ODROID Magazine te hayan dado algunas ideas sobre cómo utilizar tu ODROID-MC1 como un clúster swarm Docker y también como un clúster de computación para la programación en paralelo. Lo que puedes hacer con esto sólo está limitado por tu imaginación. Avísanos si está realmente estás interesado en información sobre cómo usar MPJ Express. Podemos crear tutoriales adicionales. Mientras tanto, disfruta y sigue explorando las posibilidades de tu ODROID-MC1.
Be the first to comment