

En mi último artículo, demostré que es bastante fácil instalar y configurar KVM e incluí algunas herramientas para crear y controlar máquinas virtuales directamente en Linux. En esta ocasión, quisiera hablar de algunas características avanzadas que puedes usar con KVM de forma gratuita, que en otros hipervisores solo están disponibles en ediciones empresariales de pago, además de cómo controlar KVM en una instalación "básica" en lugar de un sistema gráfico. Este artículo incluye muchas descripciones técnicas, las cuales están marcadas como tales. Si solo quieres configurar las cosas para que funcionen, simplemente omite estas secciones.
Recapitulando
Recordemos lo que aprendimos la última vez sobre KVM, QEMU y libvirt. KVM: la técnica que utilizamos para virtualizar sistemas directamente en el kernel de Linux (similar a VMWare o Virtualbox). QEMU: se utiliza para emular ciertos tipos de hardware en combinación con la virtualización KVM, permite funciones avanzadas como instantáneas. libvirt: una API que utilizamos para controlar nuestras máquinas virtuales y lo que sucede a su alrededor, con virt-manager como interfaz gráfica.
Segundo Escenario
En este segundo escenario, quiero aprovechar al máximo algunas de las capacidades que te permiten usar KVM en un entorno de producción. Añadiremos un segundo ODROID-H2 a la configuración, experimentaremos con almacenamiento compartido en nuestras imágenes, así como mover un sistema en ejecución de un ODROID a otro sin interrupción. Quiero analizar virsh, el cliente de línea de comandos de libvirt que nos permite controlar máquinas virtuales desde la línea de comandos y nos permite realizar algunas configuraciones avanzadas. Y controlar nuestras máquinas virtuales desde un PC remoto y no localmente en cada host. Al final, deberías saber bien cómo usar KVM incluso en un entorno de producción en tu lugar de trabajo.
Requisitos
- 2x ODROID-H2
- 1x PC/Servidor para almacenamiento compartido
- 1x PC para control remoto de nuestra configuración (yo usaré mi portátil)
- switches de red (con uno es suficiente, en un entorno de producción deberías contar con al menos dos)
- Conexión a Internet
En este segundo escenario, agregaremos un segundo ODROID-H2 a nuestra configuración para disponer de múltiples "nodos” en los que ejecutar máquinas virtuales. También uso un ODROID-N1 con un SSD conectado a modo de sistema de almacenamiento compartido que podemos usar para ejecutar nuestras máquinas virtuales. En lugar de trabajar directamente en los ODROID, me conectaré a ellos directamente en remoto desde mi portátil usando SSH. Para esto también instalé Debian Buster en el segundo ODROID-H2; esta vez la instalación será de servidor sin un escritorio X11 como MATE (que teníamos en el primer ODROID-H2), y sin el administrador de red o el virt-manager completo. Esto significa que la instalación es mucho más liviana, usa mucha menos RAM y cuenta con menos puntos críticos ante un posible ataque contra el sistema. Es muy similar a lo que se obtiene cuando se instala VMWare u otros hipervisores, que también simplemente instalan un Kernel y las aplicaciones básicas necesarias para ejecutar VM.
Instalación
Asumiré llegados a este punto que ya dispones de una instalación de servidor Debian (o Ubuntu) funcional para continuar con los siguientes pasos. Como he comentado, volví a usar Debian Buster, esta vez como servidor sin administrador de red o entorno de escritorio X11. Recomiendo encarecidamente utilizar el mismo sistema operativo en todos tus nodos y no mezclar Ubuntu y Debian u otros entornos, ya que la versión qemu utilizada probablemente será diferente y puede causar problemas en nuestro escenario. También ejecutaré todos los comandos como "root" en mi sistema, de modo que deberías saber cómo iniciar sesión como root o usar sudo para convertirse en root. Comencemos con la instalación de libvirt y las herramientas necesarias:
$ apt install libvirt-daemon-system $ rebootLa instalación del libvirt-daemon-system es suficiente, ya que viene con todas las herramientas necesarias para ejecutar y controlar máquinas virtuales (como virsh, el cliente de línea de comandos).
Configuración de red avanzada
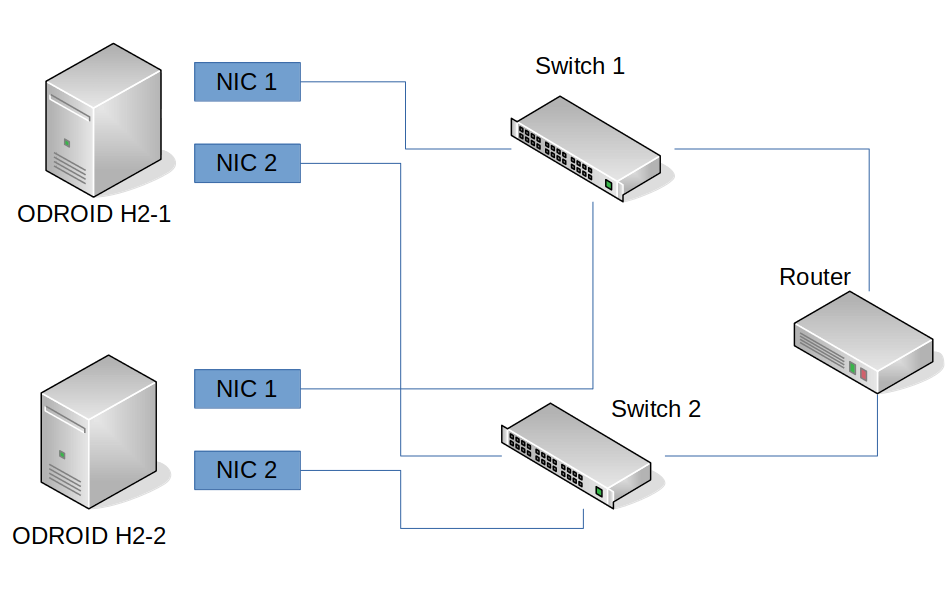
Con el fin de crear un entorno lo más parecido a "producción", analizaremos las configuraciones de red de nuestros ODROID. El ODROID-H2 tiene dos adaptadores de red (NIC) integrados. Sería un desperdicio no aprovechar esta situación. Por lo tanto, vamos a crear algo llamado "enlace", que es la combinación de los dos (o más, si fuera necesario) adaptadores de red en un enlace "virtual" (adaptador de red). Esto nos brinda diferentes escenarios de respaldo, en caso de que falle algo de la infraestructura bajo la cual se sustenta tu entorno de producción. También configuraremos algo llamado "puente" que actuará como un switch virtual para nuestras máquinas virtuales, lo que nos permitirá colocar las máquinas virtuales "lógicamente" en nuestra red, en lugar de utilizar NAT.
Descripción técnica
Si está familiarizado con, por ejemplo, VirtualBox o VMWare, deberías saber que las dos configuraciones de red más utilizadas son Bridge o NAT. NAT significa Traducción de direcciones de red, y es una técnica gracias a la cual la VM (o VMs) subsiste dentro de tu propia red privada, creada por el hipervisor (VirtualBox, VMWare, KVM, etc.), no está directamente conectada a tu red, pero usa la red del sistema host para comunicarse con el mundo exterior. Lo que significa que comparte la conexión a Internet de tu host, y normalmente tiene acceso a la misma red y sistemas a los que tiene acceso tu sistema host, pero por otro lado no se puede acceder directamente desde otras máquinas, ya que la IP de la VM no está dentro de tu red. De hecho, cada vez que la VM accede a algo en la red, la red lo ve como tráfico entrante desde su sistema host, no desde la VM. Eso es lo que NAT hace por ti. Las redes puenteadas, actúan a modo de switch virtual, que está conectado a su red física. Esto significa que, cuando una VM solicita una IP, ya no le pregunta al host, sino a tu router de red. Obtendrá una IP y la configuración del mismo router del que tu sistema host obtiene su IP. Esto te permite controlar la IP que asigna tu router, y también que otras máquinas de la misma red puedan acceder a ésta.
Comencemos
En la mayoría de los casos dentro de un entorno de producción, desearás tener una red puenteada para tus máquinas virtuales que te permitirá que otros puedan acceder a los servicios que se ejecuten en tus máquinas virtuales. También crearemos un puente de red para KVM y así las nuestras máquinas virtuales podrán conectarse directamente a tu red doméstica o a la red de tu empresa, dependiendo de dónde quieras usar esta configuración. Para ello, necesitaremos instalar algunos paquetes adicionales:
# for creating bonds $ apt install ifenslave # for creating bridges $ apt install bridge-utilsNecesitamos editar /etc/network/interfaces en ambos ODROID para configurar nuestra red avanzada. Ten en cuenta que la configuración de los adaptadores de red en /etc/network/interfaces deshabilitará el acceso del Administrador de red a estos dispositivos.
/etc/network/interfaces
# This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* auto lo iface lo inet loopback auto bond0 iface bond0 inet manual bond-slaves enp2s0 enp3s0 bond-primary enp2s0 bond_mode balance-alb auto br0 iface br0 inet static bridge_ports bond0 address 192.168.0.115 netmask 255.255.255.0 gateway 192.168.0.10
Descripción Técnica
El texto anterior es el contenido del archivo /etc/network/interfaces, así que vamos a explicar algunas de sus líneas: bond-slaves enp2s0 enp3s0 – Esta es una lista de NICs que se combina como un enlace. Los dos NIC en mis ODROID se encuentran bajo el nombre enp2s0 y enp3s0, algunos recordareis nombres como eth0 y eth1, enp2s0 es básicamente el nuevo eth0 y así sucesivamente.
ond_mode balanced-alb – Describe cómo el adaptador de red debería funcionar en conjunto. En: https://www.kernel.org/doc/Documentation/networking/bonding.txt encontrarás una descripción detallada de cómo funciona la estructura dentro del Kernel y cuáles son los diferentes modos
Un uso muy común es, por ejemplo, que el modo 1 (copia de seguridad activa) en el que un NIC siempre está ON y envía y reciba datos, pero si por alguna razón esto no es posible, cambiará al segundo NIC. Esta es una situación de espera activa para los adaptadores de red.
Hay un par de modos interesantes, por ejemplo, el modo 0 (balance-rr), el modo round-robin tiene la capacidad de acelerar bastante la comunicación. Cuando conecté mis dos ODROID H2 con el modo balance-rr y usé iperf3 para probar la velocidad de conexión, logré una velocidad de conexión de hasta 1.9 Gbit entre ambos ODROID. Lo que significa que realmente podía usar la velocidad completa de los dos adaptadores de red para que se comuncaran entre sí, pero también pude comprobar que la cantidad de errores durante el envío aumentó en consecuencia. Una máquina virtual que se ejecuta en el sistema con un adaptador de red en puente ya no podía comunicarse con el router dentro de mi red, pero si usamos la red NAT en la máquina virtual, no tendremos ese problema. De modo que, aunque logremos aumentar considerablemente la velocidad entre los diferentes ODROID, el uso está limitado.
Otro modo interesante de conexión es el modo 4 (802.3ad), que es una técnica que ha cambiado su nombre por 802.1ax. De modo qué, si tu router admite el estándar 802.1ax, eso significa que es compatible con 802.3ad, lo cual es algo confuso. Es la supuesta agregación de enlaces, es posible utilizar ambos NIC para comunicarse y, por lo tanto, "técnicamente" duplicar tu ancho de banda. No implica tener una velocidad de conexión de 2 Gbit entre ODROID, pero si que significa que puede tener dos (o más, dependiendo del número de NIC) conexiones con 1 Gbit al mismo tiempo. Entonces, en lugar de una máquina que puede conectarse a un ODROID que tiene dos NIC con 1 Gbit, puede tener DOS dispositivos conectados al mismo tiempo, AMBOS con 1 Gbit. Sin embargo, requiere switches de red que admiten esta configuración y algunos preparativos.
bridge_ports bond0 – este es el adaptador de red para tu switch virtual (el adaptador puente). También podría ser directamente enp2s0 o enp3s0, pero usando un enlace, nos aseguramos de que, si un adaptador no tiene conexión, el otro adaptador pueda mantener nuestra red en funcionamiento.
Yo he utilizado una configuración de IP estática para mi puente, ya que siempre quiero tener la misma IP. Tambien podría haber optado por usar iface br0 inet dhcp para una configuración automática. El enlace está configurado en iface bond0 inet manual ya que no necesita una IP. El adaptador puente mantendrá la IP para el enlace, por así decirlo.
En el mejor de los casos, deberías conectar tus ODROID a dos switches de red diferentes que están conectados a tu router. De esta forma, si uno de los switches muere, los ODROID seguirían funcionando con el otro router. Razón principal para tener varios enlaces y modos como active-backup. También nos permite actualizar el firmware de los switches y reiniciar sin perder la conectividad de las máquinas virtuales que se estén ejecutando en tus hosts KVM
La configuración en su totalidad también funcionará con un switch. No necesita dos switch, ni siquiera necesitas conectar ambos adaptadores LAN del ODROID-H2.
Acceso remoto
Como he dicho antes, ahora dispongo de más máquinas en la configuración y sería práctico conectar cada sistema a un televisor o monitor con su propio ratón y teclado para configurarlos. De modo que, quiero poder conectarme a cada dispositivo de forma remota desde mi portátil que ejecuta Ubuntu 18.04. Usar SSH me permite conectarme a mis ODROID de forma remota para configurarlos a través de la red. Creé una clave SSH en mi ordeandor portátil (si aún no lo ha hecho, puede usar el siguiente comando para generar una nueva clave ssh:
$ ssh-keygenEsta clave se distribuye con el siguiente comando a los dos dispositivos ODROID-H2:
$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@< server-ip >Esto me permite iniciar sesión como root a través de SSH usando mi clave SSH en lugar de una contraseña. En general, es una forma más segura que usar una contraseña. De hecho, hice esto antes de empezar a configurar la red e instalar aplicaciones en los ODROID. Esto también me permite usar el administrador de máquina virtual de forma remota.
Una vez que hemos instalado los paquetes necesarios para KVM y libvirt y hemos configurado la red como he descrito anteriormente, podemos usar virt-manager para controlar nuestros hosts. Para esto, simplemente inicia virt-manager en el sistema que desees usar para controlar tus ODROID (en mi caso es mi ordenador portátil). Haz clic en “File” en el menú y selecciona “add connection”. Marca la casilla que deseas conectar a un host remoto, el usuario debe ser root, luego simplemente introduce la IP de tu ODROID H2 en nuestra configuración. Repite el mismo proceso para el otro ODROID-H2. Con esto ya tenemos los ODROID en forma de lista dentro de nuestro administrador de máquina virtual.
Puedes marcar la casilla que debería conectarte automáticamente, o simplemente haz doble clic en los ODROID de la lista para conectarte a los mismos. Debería verse exactamente igual que cuando usaste virt-manager localmente en el primer escenario, solo que ahora tiene dos ODROID para trabajar y crear máquinas virtuales.
Como puede ver, es bastante fácil conectarse a varios hosts, así como controlar y crear multitud de máquinas virtuales en tu red. Esto simplemente te permite ahorrar tiempo, dinero y recursos para usar máquinas virtuales en la red de tu casa o empresa. Teniendo en cuenta que puede ejecutar todo esto en una simple imagen de servidor, sin tener que instalar herramientas gráficas para configurar tus máquinas virtuales en el propio host, se acerca bastante a la forma en que se ejecutan VMware, Xen y otros hipervisores con soluciones "básicas".
Configurar un almacenamiento compartido
Aunque ya podemos realizar bastantes cosas en nuestro actual escenario, hay mucho más que podemos hacer usando KVM y libvirt. Para ello quisiera usar un almacenamiento compartido para los diferentes hosts de virtualización con los que estamos trabajando. Esto nos permitirá tener un almacenamiento centralizado para todos nuestros hosts sobre los que ejecutaremos nuestras máquinas virtuales, y nos brinda la posibilidad de ejecutar la misma máquina virtual en diferentes hosts, simplemente apuntando el host a la imagen de disco duro correcta para una determinada máquina virtual. También nos permite utilizar soluciones de red más rápidas y seguras, tales como SAN, NAS o clústeres de almacenamiento. Esto en sí mismo tiene muchos beneficios a la hora de ejecutar máquinas virtuales fuera del almacenamiento local directamente en los hosts. También reduce los costes generales, ya que no necesitas tener un almacenamiento para cada host, un sistema mínimo es más que suficiente. Puedes ejecutar todo el sistema desde un módulo eMMC de 8GB (incluso siendo más pequeño, también funcionaria) y dejar que las máquinas virtuales se ejecuten en un almacenamiento de red, con RAID, copias de seguridad, etc. Esto reduce el coste y el mantenimiento tanto del sistema de almacenamiento como de los hosts de virtualización (es decir, el ODROID). En mi configuración, utilizo un ODROID-N1 con un SSD conectado. Creé una partición en el SSD para este propósito y monté la partición en /srv/nfs. Como habrás adivinado por el nombre, he configurado un recurso compartido NFS para el almacenamiento compartido.
Instalación y configuración
La instalación es muy simple, así como la configuración. Como he dicho antes, en mi caso usare la partición montada en /srv/nfs, de modo que, si tiene una ubicación diferente, deberías modificar las rutas en consecuencia:
$ apt install nfs-kernel-server $ mkdir /srv/nfs $ chown nobody:nogroup /srv/nfs $ chmod 777 /srv/nfs $ echo "/srv/nfs 192.168.0.0/24(rw,sync,no_root_squash,no_subtree_check)" >> /etc/exports $ exportfs -a $ systemctl restart nfs-kernel-serverTen en cuenta que yo sólo permito conexiones de la subred 192.168.0.0/24. Si tu red es diferente, también necesita ajustar esto, o puedes reemplazar la subred por completo simplemente usando un asterisco (*) en lugar de /srv/nfs:
*(rw,sync,no_root_squash,no_subtree_check)Ahora que el servidor está preparado y es totalmente funcional, necesitamos preparar los dos ODROID como cliente. Para esto, necesitamos instalar el paquete nfs-common en ambos clientes y configurar libvirt para montar el soporte NFS. Para esto, usaré virsh, la herramienta de línea de comandos de libvirt. Al igual que el administrador de máquinas virtuales, esta herramienta nos permite manipular todo lo que rodea a nuestras máquinas virtuales. De hecho, es mucho más potente que el administrador de máquinas virtuales en sí.
$ apt install nfs-common
$ mkdir -p /var/lib/libvirt/shared-pool
$ echo "< pool type='netfs'>
< name>shared-pool</ name>
< source>
< host name='< server-ip >' />
< dir path='/srv/nfs' />
< format type='nfs' />
< /source>
< target>
< path>/var/lib/libvirt/shared-pool</ path>
< permissions>
< mode>0755</ mode>
< owner>-1</ owner>
< group>-1</ group>
</ permissions>
</ target>
</ pool>" > shared-pool.xml
$ virsh pool-define shared-pool.xml
$ virsh pool-autostart shared-pool
Obviamente, debes reemplazarlo con la IP de tu servidor donde se está ejecutando el NFS, igual que /srv/nfs en caso de que tu ruta al recurso compartido NFS sea diferente. Lo que estamos haciendo exactamente es crear un archivo .xml llamado shared-pool.xml, que incluirá nuestros parámetros de conexión y la ruta donde queremos montarlo. Con virsh pool-define podemos decirle a libvirt que cree un nuevo grupo de almacenamiento.
Consejos
Se pueden hacer cosas similares con una VM. Puedes, por ejemplo, volcar una configuración xml de una VM e importarla a otra máquina:
# dump a VM configuration and redirect into a file: $ virsh dumpxml --domain win10 > win10.xml # import a VM configuration as a new machine: $ virsh define win10.xmlDe esta forma, puedes hacer fácilmente copias de la configuración de una máquina sin tener que hacer la misma configuración a través del administrador de máquina virtual una y otra vez. Simplemente descárgate una configuración de VM, edita el archivo con tu editor de texto favorito. Por ejemplo, adapta la dirección MAC de la NIC y el archivo de imagen del disco duro, y tendrás una nueva VM basada en la configuración de una VM ya existente. Naturalmente, también existe una opción para clonar una VM, que también te permitiría iniciar la MISMA VM en un host diferente, siempre que la configuración exista en ambos sistemas y tengan acceso al archivo de disco duro (de ahí el uso compartido del grupo de almacenamiento en el que estamos trabajando).
Administrador de máquina virtual
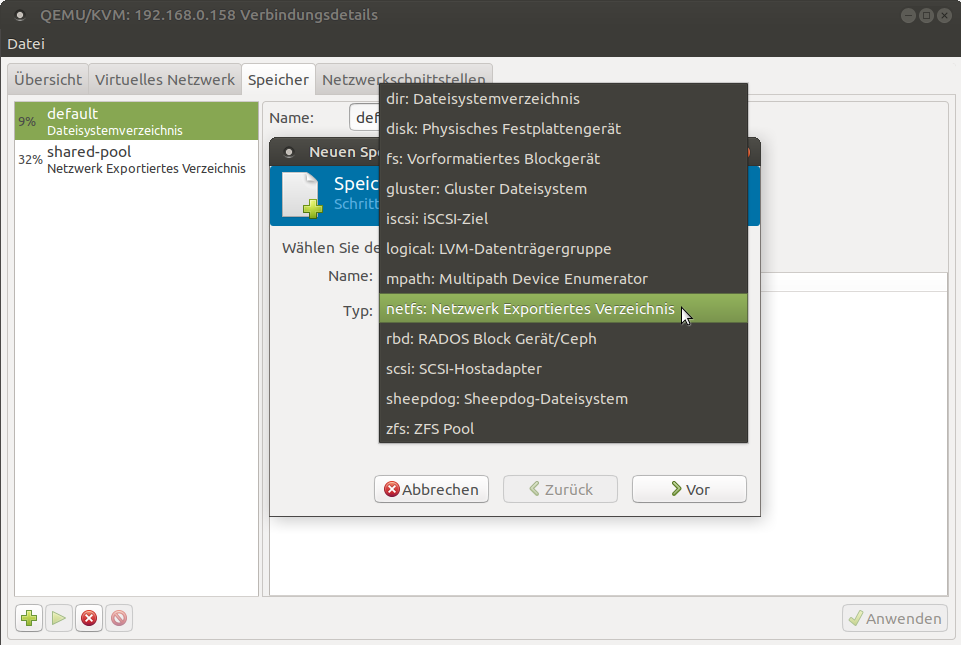
También puedes hacer lo mismo a través del administrador de máquina virtual. Como puede ver en la Figura 3, existe multitud de formatos de almacenamiento y soluciones compatibles para libvirt que te permiten configurar la solución de almacenamiento que prefieras para tu configuración. NFS es solo una de las muchas opciones que tienes. A modo de comentario, nosotros en el trabajo utilizamos un Ceph Cluster como grupo de almacenamiento para nuestros servidores KVM.
La velocidad de tus máquinas virtuales es tan buena como tu solución de almacenamiento, y si necesita la mayor velocidad posible, entonces, por supuesto, ejecutar un almacenamiento local desde un NVMe podría ser mucho mejor que ejecutar tus máquinas virtuales desde un almacenamiento compartido en red, pero también limita tus opciones a la hora de trabajar con él, y dependiendo de tu solución de almacenamiento, la velocidad puede llegar a no ser tan mala.
Usar el sistema de almacenamiento compartido debería ser lo más obvio. En lugar de crear nuevas imágenes en la ubicación por defecto, las creas en el almacenamiento compartido y estarán disponible para todos los ODROID que acceden al almacenamiento.
Migración en vivo
Para aquellos que se estén preguntando qué es la migración en tiempo real, es una técnica que permite mover una VM de un host a otro mientras el host aún se está ejecutando. Esto permite actualizar o incluso reiniciar el host sin interrumpir los servicios (VM) que estás ejecutando. Por ejemplo, si ejecuta una máquina virtual que aloja WordPress, pero necesita actualizar el host en el que se ejecutan las VM, o si desea distribuir la carga en otro ODROID, puede mover la VM (mientras se ejecuta) a otro host, y durante todo el tiempo el sistema aún está accesible. Las personas que se conecten al servidor de WordPress ni siquiera notarán que la máquina se está moviendo.
Technical description
Este escenario requiere un grupo de almacenamiento compartido, lo cual significa que todos los hosts (ODROID) tienen acceso a la imagen del disco duro. Pero los datos que están en la RAM y procesados por la CPU son únicos y esa es la parte con la que trabaja libvirt. Se copiará la configuración de la máquina (el archivo xml) de una máquina a otra y empezará un proceso de copia del contenido de la RAM de la VM que se está ejecutando actualmente de un host al otro host (un ODROID al otro). Como no necesitas copiar el sistema operativo en sí (se comparte la imagen del disco duro), incluso se podría mover una máquina virtual que tenga cientos de GB o incluso TB de datos de un host a otro, ya que únicamente debe ser copiado el contenido de la RAM. Libvirt creará una copia idéntica de la configuración de la VM de un host a otro. Esto significa que también creará el mismo hardware adicional, como por ejemplo la tarjeta de red, la tarjeta de sonido, la tarjeta gráfica, etc., para esto, los otros hosts deben tener la capacidad de ejecutar el mismo hardware virtual. Como la máquina en sí misma se está ejecutando y está realizando tareas, el contenido de la RAM puede cambiar durante el proceso de sincronización, verás como la barra de proceso cerca del final "salta hacia atrás" y continuará haciéndolo hasta que complete su tarea por completo. Esto depende de lo rápida que sea tu red entre los hosts y con qué frecuencia cambia la RAM y cuánta RAM tiene una VM. Una máquina virtual que está inactiva la mayor parte del tiempo y se ejecuta en 500MB de RAM será muy rápida de sincronizar y solo tomará unos segundos. Si ejecutamos una base de datos, un servidor de archivos o una máquina con un compilador en ejecución que carga constantemente nuevos datos en la RAM y tienes 64 GB de RAM, este proceso llevará mucho más tiempo y puede tardar varios minutos en completarse. Al final, ambas máquinas se pondrán en "pausa" durante una fracción de segundo para hacer el cambio de una máquina a otra y luego se reactivarán, como he comentato, nadie notará nada en absoluto. Esta característica también está disponible en el hipervisor VMWare, pero no sin invertir una gran cantidad de dinero; mientras que en KVM es una característica gratuita.
Cómo usar la migración en tiempo real
Para usar la migración en tiempo real, no necesites hacer mucho. Es mejor tener el modo de caché de disco para máquinas virtuales configurado en "ninguno" para la migración, ya que los métodos de almacenamiento en caché pueden causar problemas en caso de fallos. Por ejemplo, cuando migramos una máquina de un host a otro y el host falle, podría ser que los datos que aún estaban en caché se pierden y no se escriben en el disco. Esto generalmente es un problema de los métodos de almacenamiento en caché, no obstante, esta advertencia se puede ignora y forzar la migración entre máquinas. Puedes migrar máquinas a través de la interfaz gráfica desde el administrador de máquinas virtuales. Para esto, debe estar conectado a ambos hosts, hacer clic con el botón derecho en la máquina virtual que deseas migrar de un host a otro y selecciona “migrate”. Luego selecciona el host al que deseas migrar de la lista desplegable y haga clic en “start”. En las opciones avanzadas, puede activar que quieres migrar incluso si se está utilizando un algoritmo de almacenamiento en caché de disco "inseguro". Otra posibilidad es usar nuestra herramienta de línea de comandos virsh para migrar una máquina. Para esto, inicia sesión a través de ssh en el host donde se esté ejecutando la VM y usa el siguiente comando:
# Syntax $ virsh migrate --verbose < VM> qemu+ssh:// /system # example: $ virsh migrate --verbose win10 qemu+ssh://192.168.0.115/systemPuedes añadir el parámetro --unsafe para permitir la migración con métodos de almacenamiento en caché de disco inseguros.
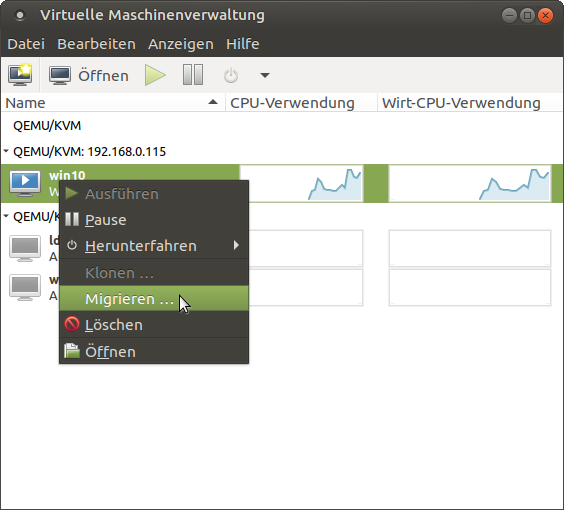
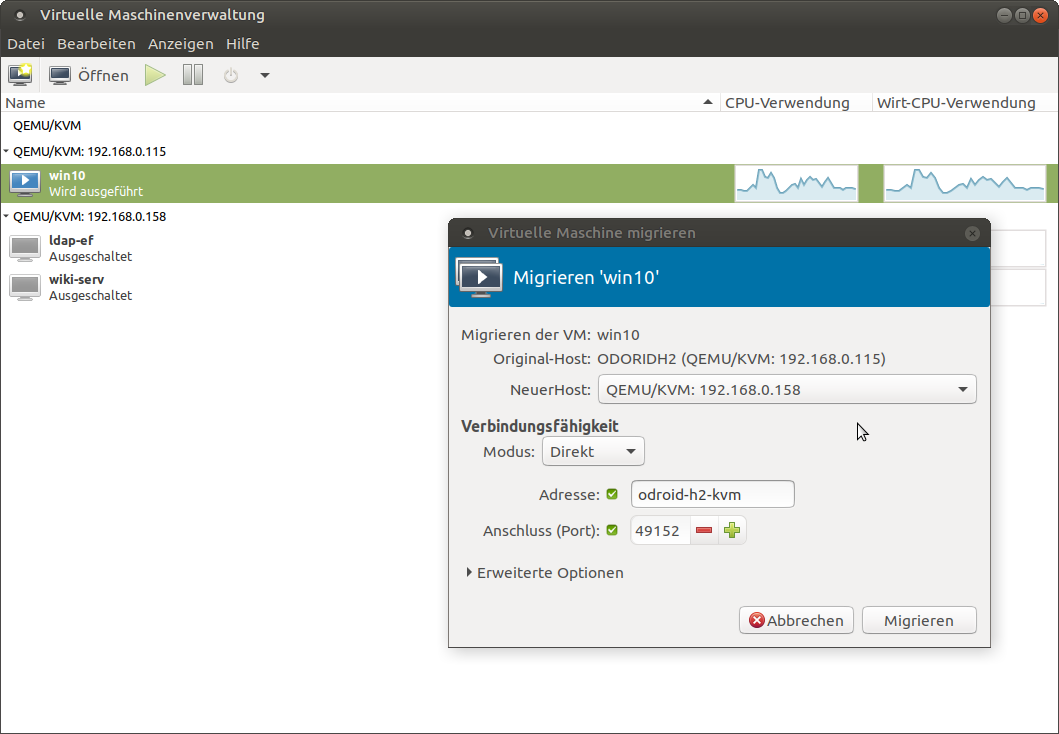
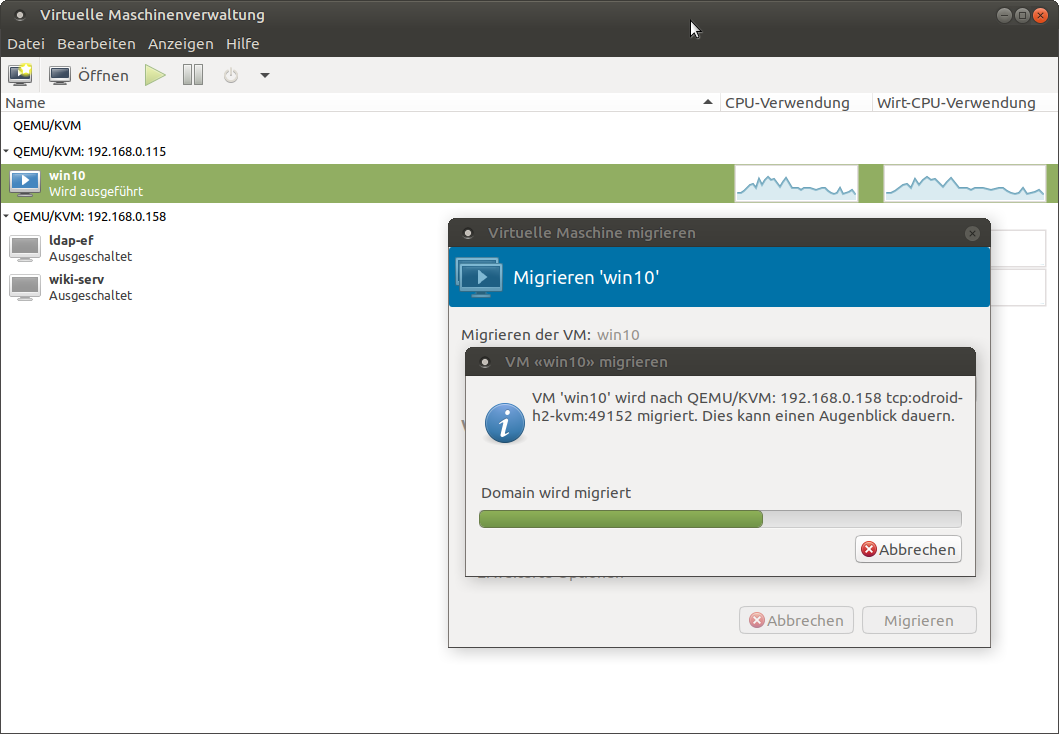
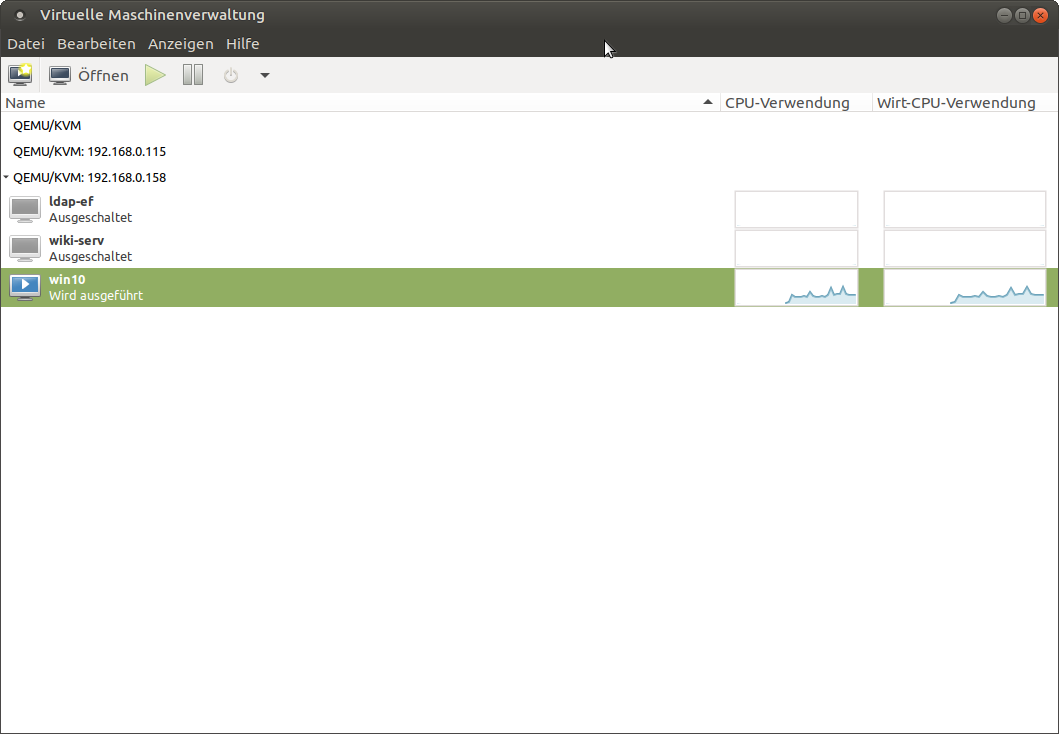
Como puede ver, el proceso es bastante simple y directo. No hay mucho en lo que prestar atención. Una vez que configures el grupo compartido y los dos hosts KVM están en la misma red y pueden mover datos entre sí, no hay nada que impida mover una máquina de un host a otro mientras aún esté en funcionamiento.
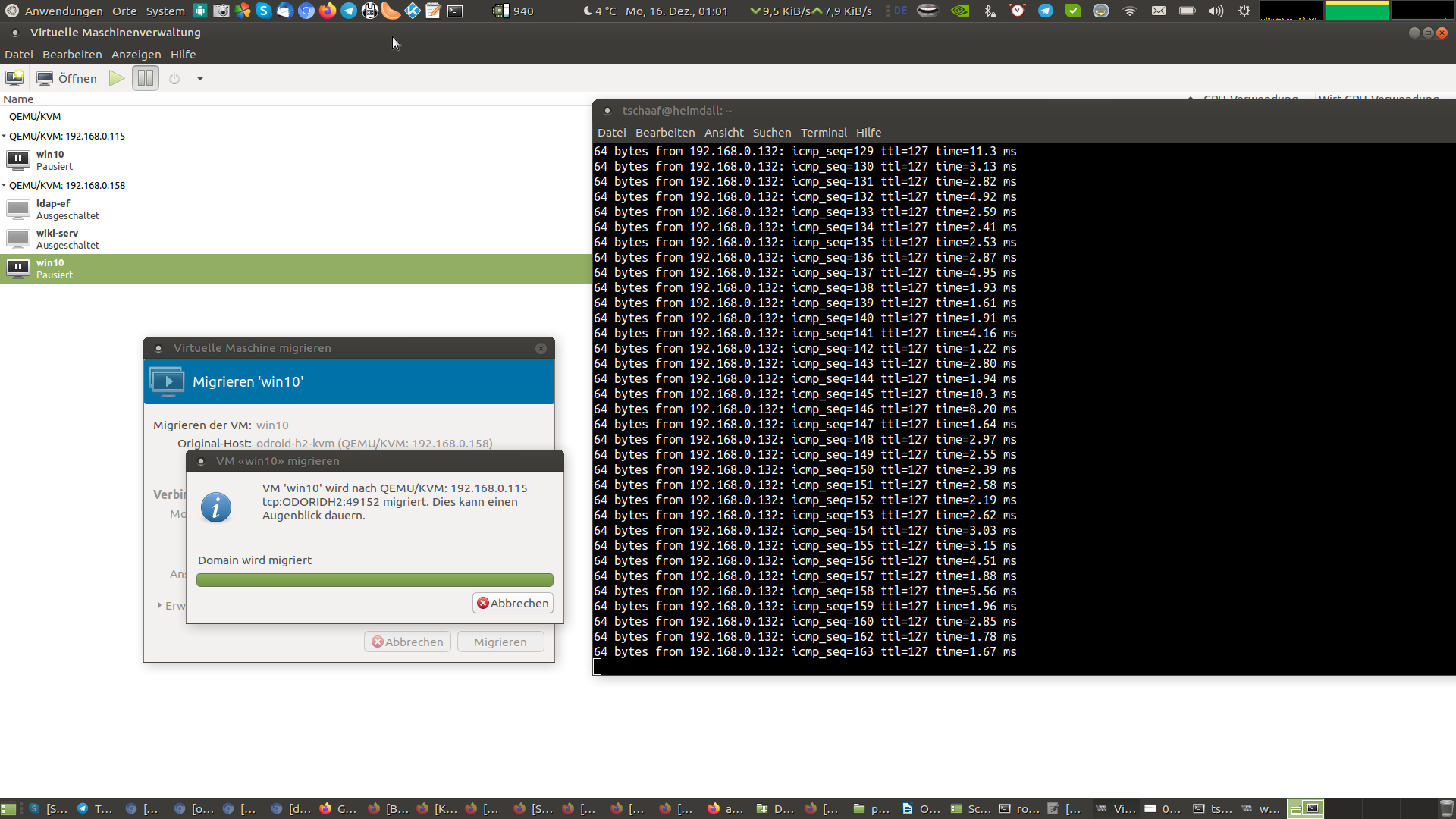
La captura de pantalla de la Figura 10 se tomó en el momento en que finalizó el proceso de migración y se cambió la VM. Un único ping no llego a completarse. Imagina que alguien acceda a un servidor de WordPress que se está migrando. Este retraso de un ping ni siquiera se notaría en una carga de trabajo normal y el usuario nunca sabría que se acaba de mover todo el sistema de un host a otro. De hecho, utilizando una conexión de fibra, incluso se podría migrar máquinas virtuales fácilmente entre diferentes ubicaciones o centros de datos.
Conclusión
Con esto, hemos aprendido a configurar un entorno de producción para nuestras máquinas virtuales. Ahora deberías poder compartir máquinas virtuales en tu red para proporcionar servicios a todos tus clientes, o usar esto para alojar un amplio espectro de servicios on line utilizando redes puenteadas. También debe saber cómo configurar grupos de almacenamiento compartido para aprovechar el almacenamiento de red, como un SAN o NAS o un simple recurso compartido NFS. Además, deberías haber aprendido cómo migrar máquinas virtuales entre diferentes hosts, lo cual te permite realizar tareas de mantenimiento o distribuir la carga de máquinas virtuales entre diferentes hosts. Todo esto se puede lograr en tu ODROID-H2 u otros PC/Servidores con la ayuda de KVM como motor de virtualización (hipervisor). Hay un montón de documentación sobre este tema y te recomiendo que leas más sobre ello si esta guía te ha despertado la curiosidad.
Optimización
Hay muchas cosas que puede cambiar en libvirt para aumentar el rendimiento en diferentes escenarios. El algoritmo de almacenamiento en caché para el disco virtual, por ejemplo. Quisiera hablar un poco sobre la optimización de la CPU y sobre la "emulación" de la CPU en KVM o, mejor aún, QEMU. He comentado con anterioridad que QEMU se usa para "emular" el hardware, y KVM se usa para la parte de virtualización. Aquí nos encontramos con algo único de solución KVM. En lugar de pasar por la CPU EXACTA que tu host ofrece, como a menudo se hace con VirtualBox y otra solución de hipervisor, QEMU "emula" una CPU pero pasa a través de las funciones de la CPU que soporta. ¿Por qué emular y no pasar? La respuesta es simple. ¡Portabilidad! Imagine el siguiente escenario: Tienes un servidor de presupuesto pequeño muy reciente para fines de prueba, digamos, por ejemplo, con un procesador Intel® Xeon® E-2226G de 2019 con 64 GB de RAM que utilizas para probar la configuración de un nuevo sistema, por ejemplo, un nuevo servidor de base de datos MSSQL de Windows, y después de las pruebas, desea mover la VM a un servidor más antiguo pero más potente que ejecute un sistema de procesador dual alimentado por dos procesadores Intel® Xeon® Processor E5-2697A v4 de 2016 con 1TB de RAM como entorno de producción. En muchos escenarios, tendría que configurar la VM nuevamente en el Servidor más antiguo, ya que el E-2226G basado en Coffee Lake más nuevo tiene algunas características de CPU que no están disponibles en el E5-2697A basado en Broadwell antiguo. Windows no solo requeriría una reactivación debido al cambio de CPU, en el peor de los casos, el sistema se comporta de manera muy diferente al escenario probado, sino que probablemente no podrá mover la VM mientras aún se ejecute de un servidor a otro. otro, ya que los sistemas son tan diferentes que la transferencia fallará. Aquí es donde QEMU y KVM funcionan de manera diferente. Si revisas la lista de CPU en las opciones del administrador de la máquina virtual, verás que hay una lista bastante extensa de CPU, tal y como se muestra en la Figura 11.
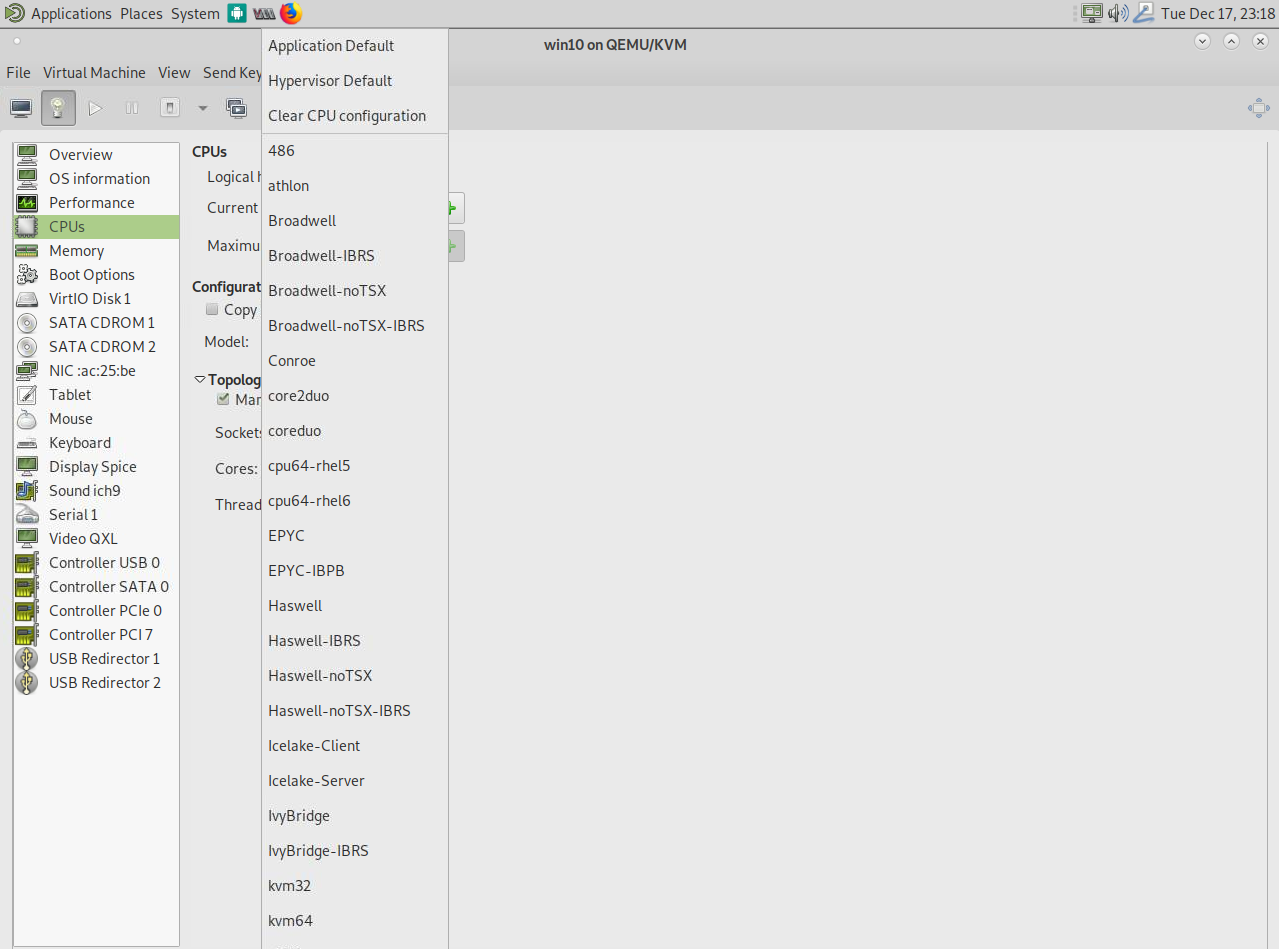
Lo que esto significa es que puedes crear una VM con una CPU emulada que sea compatible con ambos servidores (por ejemplo, Broadwell-IBRS). Este doble soporte permite configuraciones de prueba que son iguales en ambos sistemas y permite la migración en tiempo real de la VM de un host a otro sin interrumpir el servicio (como se ha explicado anteriormente) incluso si los servidores se ejecutan en arquitecturas de CPU completamente diferentes. Siempre que encuentre un denominador común más pequeño en la arquitectura de la CPU, puede configurar una VM con esto y migrar máquinas entre estos servidores de todos modos. ¿Como funciona? Si analizas el resultado del siguiente comando, probablemente habrás notado que esta línea "flags" aparece para cada CPU:
$ cat /proc/cpuinfoEstas son las características que admite tu CPU. Incluso las placas ARM tienen esta línea, que muestra qué técnicas entiende y admite la CPU.
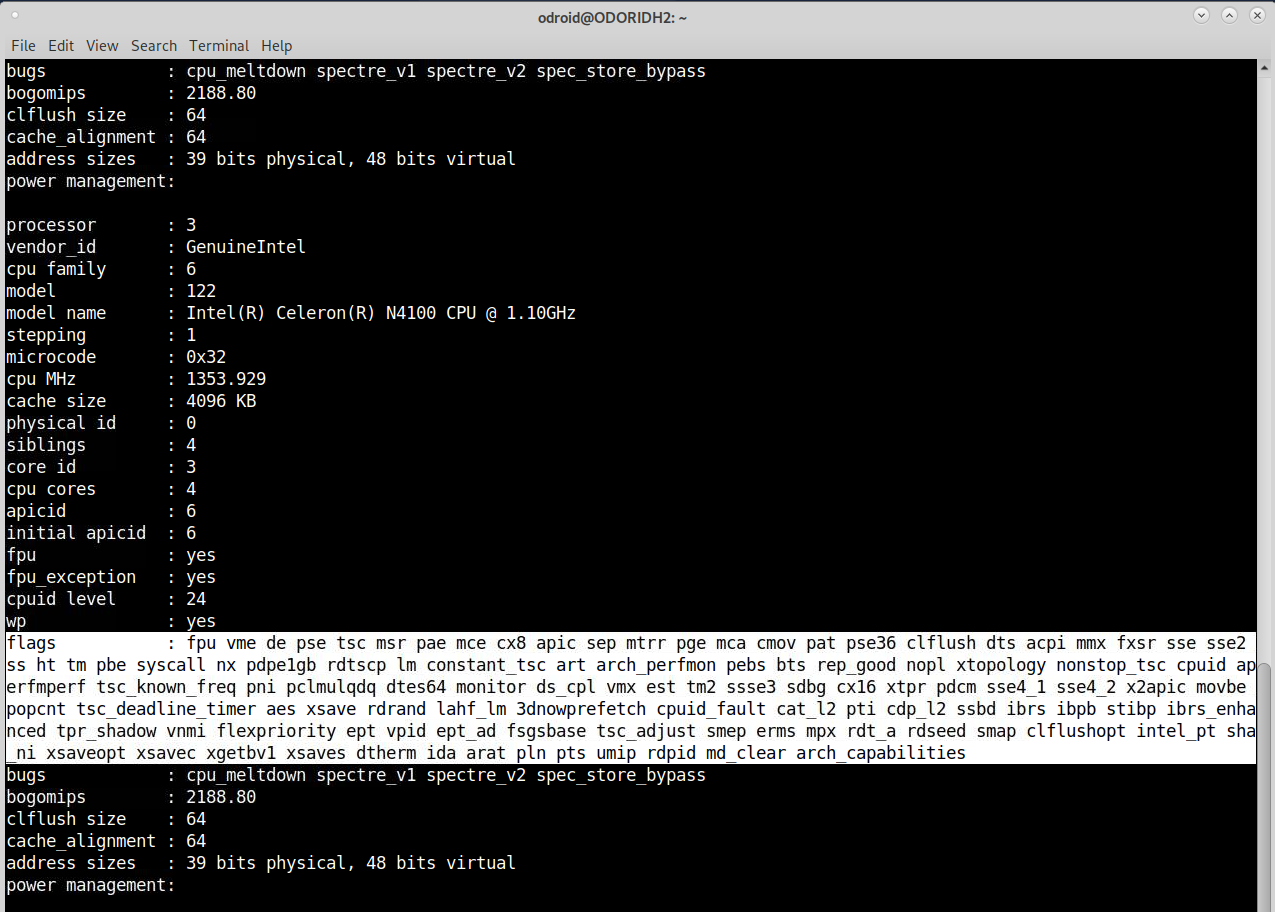
Ciertas arquitecturas de CPU presentan diferentes tipos de indicadores de CPU. Broadwell tiene menos funciones como, por ejemplo, Skylake, aunque más funciones que una CPU SandyBridge, y éstas dependen QEMU y KVM. Dependiendo de la arquitectura de CPU que selecciones, los indicadores "bien conocidos" se enviarán como características de CPU a la VM. Por lo tanto, reenviar las capacidades de rdseed de tu CPU a la VM puede aumentar el rendimiento de cifrado a medida que añades un generador adicional de números aleatorios a tu sistema para obtener más entropía. Una característica que no estaba presente en una CPU SandyBridge antigua, por ejemplo. ¿Cómo usarlo en el ODROID H2? El problema con el ODROID H2 es que no es una placa de servidor real, en algunos casos ni siquiera es un procesador de escritorio real, por lo que pierdes algunas características de CPU que esperarían presentes en este tipo de dispositivos. La virtualización está optimizada para el entorno del servidor y las placas como ODROID H2 no coinciden con esta descripción, por eso tenemos que solucionar algunas cosas para que funcione correctamente. Por defecto, la CPU debe mostrarse como Westmere o IvyBridge-IBRS, ya que estas son las CPUs que KVM encontrará como compatibles de forma predeterminada, pero eso es solo porque es donde encuentra TODAS las características de la CPU que espera. Inclujso si no encuentra algunas características, no significa que no sea positivo utilizar una arquitectura de CPU más alta
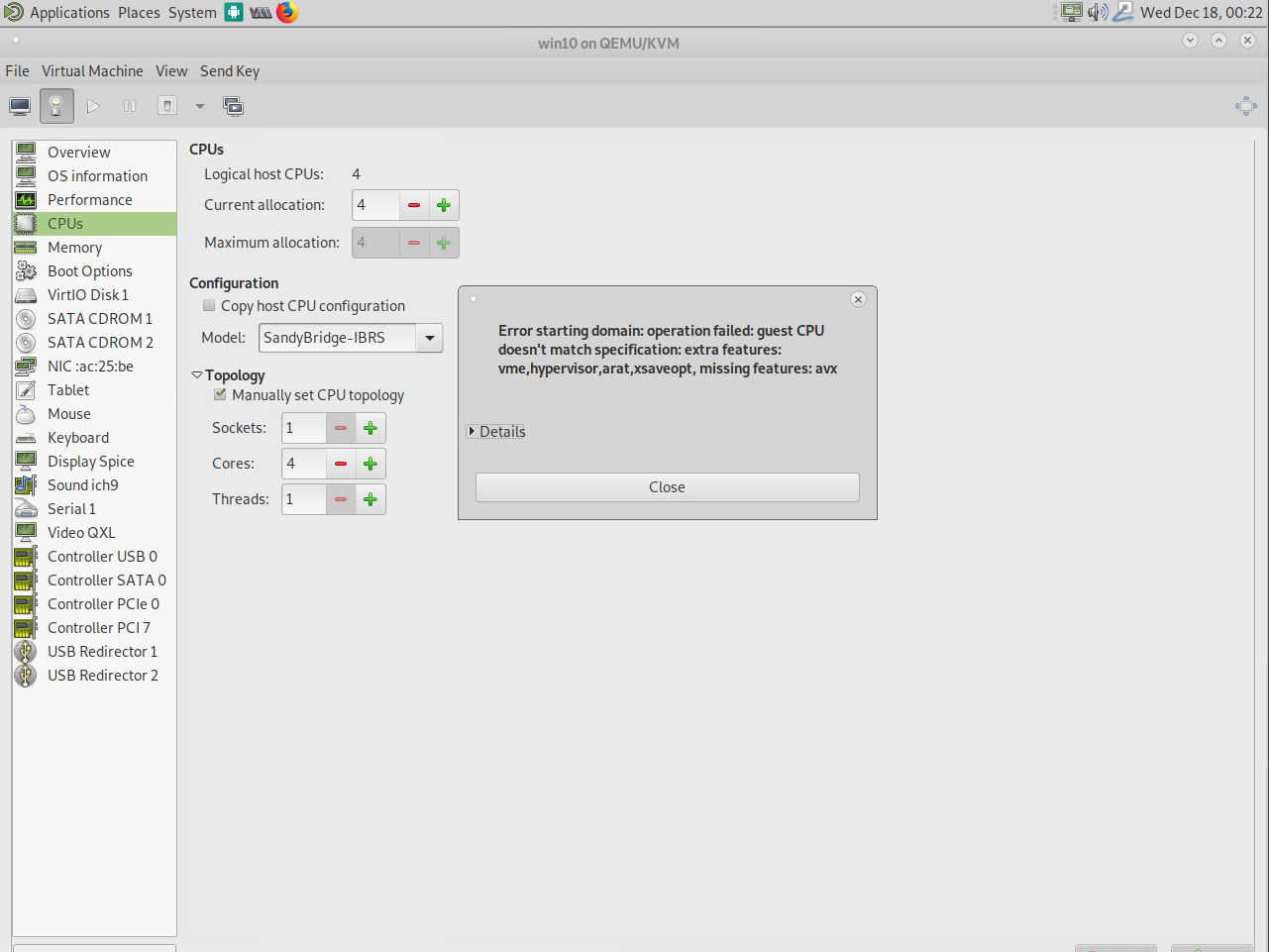
Aquí podemos usar virsh nuevamente para configurar opciones específicas como una solución alternativa. Como expliqué antes, los diferentes tipos de CPU son una combinación de diferentes indicadores de CPU. Esto nos dice que nos falta la función avx que, si la comparamos con los indicadores del ODROID-H2, es cierto que falta esta función. Podemos agregar ésta a la configuración de la máquina. También existe una lista de características adicionales que utilicé, pero que no forman parte de la configuración de SandyBridge y, por lo tanto, deben añadirse manualmente. Con el siguiente comando, podemos editar la configuración de la VM directamente:
$ virsh edit --domain win10
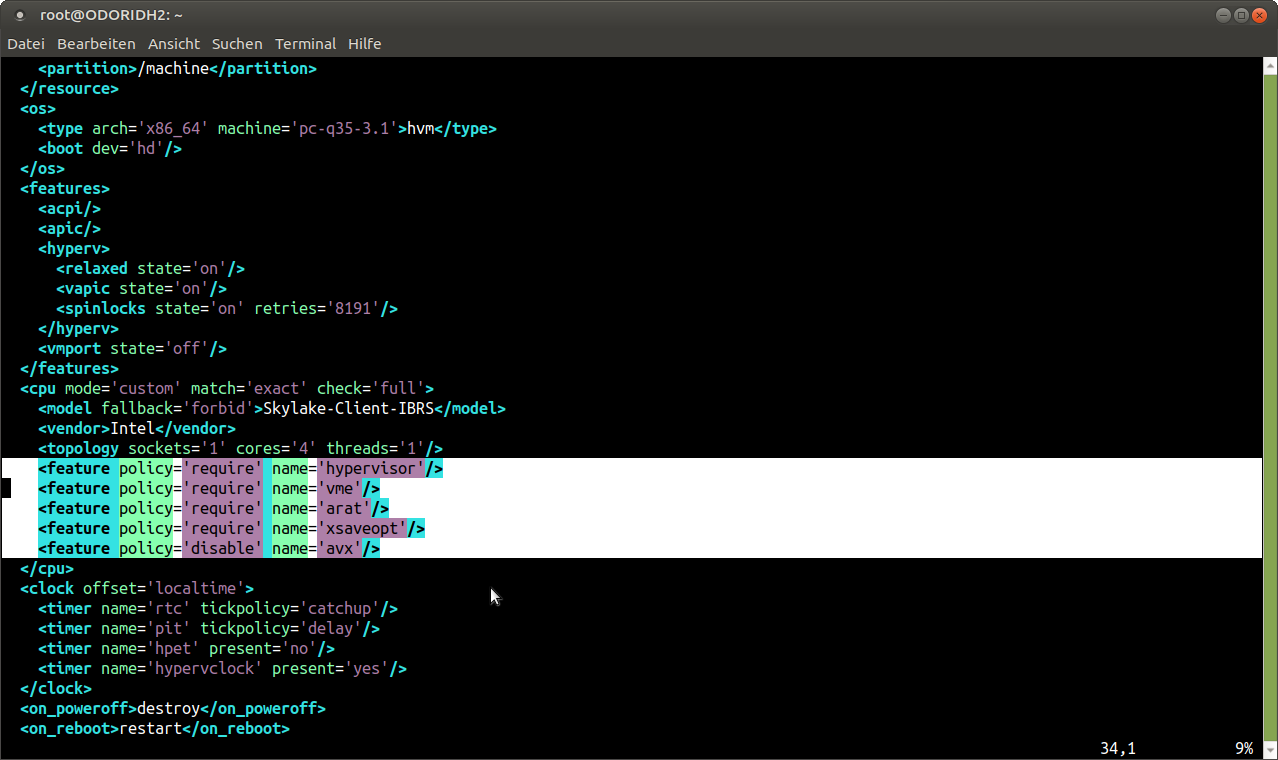
Entre el indicador < feature policy='disable' name='avx' />
Con este ajuste, podemos usar una CPU SandyBridge en nuestra VM incluso si no todas las funciones son compatibles. De hecho, pude ejecutar Skylake-Client-IBRS deshabilitando las siguientes funciones:
< feature policy='disable' name='avx' />
< feature policy='disable' name='avx2' />
< feature policy='disable' name='fma' />
< feature policy='disable' name='pcid' />
< feature policy='disable' name='bmi1' />
< feature policy='disable' name='bmi2' />
< feature policy='disable' name='invpcid' />
< feature policy='disable' name='f16c' />
< feature policy='disable' name='hle' />
< feature policy='disable' name='rtm' />
< feature policy='disable' name='adx' />
< feature policy='disable' name='abm' />
Sugiero agregar la función "hipervisor", ya que generalmente muestre que la máquina es una VM.
Información general Puedes hacerte una idea de lo que es posible y cuáles son las CPU compatibles más recientes al consultar este enlace: https://www.berrange.com/posts/2018/06/29/cpu-model-configuration-for-qemu-kvm-on-x86-hosts/. Es importante habilitar algunas funciones que pueden decirle a un Invitado que no necesita corregir algunos de los errores recientes de Intel, como Spectre. Existe un microcódigo que funciona entorno a este error disponible en el SO. Este microcódigo normalmente reduce el rendimiento de la CPU hasta cierto punto. Si ejecuta una VM, la VM no es consciente del hecho de que este "error" no está presente en la CPU (arreglado por el microcódigo en el host) e intentaría solucionarlo también con su propio microcódigo. Para esto, encontrarás algunos indicadores de CPU en el sitio anterior que le indican a la máquina virtual que este error ya está solucionado, que puedes añadir con el indicador "require". También encontrarás opciones para procesadores AMD en el sitio anterior. Una vez más, esta es una característica en la que debes profundizar si deseas obtener más información al respecto.
Conclusión
Sumergirme en KVM y libvirt ha sido una experiencia muy interesante. La capacidad de migrar máquinas virtuales sobre la marcha sin interrumpir el servicio es una característica muy interesante y muy útil en un entorno de producción. En el trabajo, lo hemos estado usando durante años. En combinación con Ceph u otras soluciones de almacenamiento de bajo coste, es una alternativa buena y barata a VMware, por ejemplo, con muchas características a nivel empresarial. Puesto que se ejecuta directamente en Linux, un servidor Debian o Ubuntu estándar con casi nada instalado ya es suficiente para ejecutar y proporcionar una buena base para administrar tus hosts y máquinas virtuales. Proporciona controladores y kernels actuales con parches de seguridad, no teniendo que pasar por el bloqueado de soluciones como VMWare, donde debes esperar a que proporcionen soporte de hardware y parches de kernel para tu software.
Be the first to comment